AI Security Vulnerabilities: Understanding Risks, Threats and Mitigations
Learn the most critical AI security vulnerabilities, including prompt injection, data leakage, model manipulation, and agentic AI risks, plus mitigation strategies.

Bhagyashree

Today, enterprises deploy large language models, generative AI, and autonomous agents for support, code creation, and decision-making. That is exceeded by the number of controls in place to safeguard it, with any potential vapors in AI security features transitioning from a research curiosity to a risk that goes onto the board's agenda. These vulnerabilities are more nuanced than the types of bugs that security teams are familiar with. A classic bug is in stationary code that you can scan and patch. The drawback of AI is that it is probabilistic: its outputs change with learning and action, the way it moves around, its capabilities change as it moves, and so on. This guide serves as an introduction to what AI security vulnerabilities are, how the attack surface is growing with agents and integrations, the crucial types of vulnerabilities, how AI vulnerabilities affect businesses, and the likely defenses that will stand up to the attack in 2026. You'll also receive an actionable checklist to use immediately.
What are AI Security Vulnerabilities?
AI security flaws include areas where AI systems fall short in accepting inputs, reasoning, and producing outputs, as well as in interacting with the world. That's possible, whether you're changing behavior in LLM or GenAI type models, are inserting a bit of information the model has seen in the prompt already, or attempting to get a "maturity element" out of it that it wouldn't otherwise include. The tools, APIs, and memory in AI agents are extended, and a single manipulated instruction may cause actual actions to happen.
What makes it different from traditional application vulnerabilities is where the flaw is found. A classic web bug is deterministic – it means that if you hit it one time, you'll always get the same thing back, and if you patch it, it'll never return. The same input can generate different outputs, and AI-native risks aren't necessarily in the code, but can stem from access to tools, reasoning, and/or data.
Why AI Systems Introduce New Cybersecurity Risks
The vulnerabilities of AI cybersecurity lie in its very attributes of utility. Dynamic outputs generate outputs instead of retrievals and can therefore be manipulated by the attacker. There is probabilistic behavior involved in the results, and they are difficult to test the first time set. External tool integrations add functionality to allow models to query databases, call APIs, and run code, converting a weakness into an action. If you have an agent that is supposed to submit steps that are autonomous (meaning not reviewed by humans), you don't need to review every step like you would with a human, which could lead to small mishaps getting amplified.
Why Traditional Security Models Fail for AI Applications
Static controls are designed to provide the same responses to an application regardless of usage, but that is not the case with AI. If the prompt injection is given in another sequence of characters, it will not be recognized by an application firewall unless it’s a signature that has been programmed into the WAF. Another security issue is the visibility gap in agentic systems, where the agent's actions often appear in the security team's view, but not necessarily the reasons that drove the agent to invoke that action; the intent behind the action is often not visible. One of the most difficult GenAI security problems is reasoning carried out during the run time – i.e., when the model makes decisions on its own, not yours – which must be monitored.
The Expanding AI Attack Surface
Understanding AI Agent Attack Surfaces
AI agents have larger attack surfaces than just one model endpoint. Each connection an agent uses is a way in:
APIs that the agent calls to read or update information
Extensions that augment the control set of the agent.
Browsers, Connectors that are pulling in external content.
Vectors as embeddings stored, and retrieved with context.
Multi-agent orchestration systems with knowledge passing agents that hold all the knowledge desirable to do the world.
Each item on that list can be probed, poisoned, or misused, not to mention the fact that most of those are not contained within the model itself.
Risks Introduced by Agentic Workflows
Agentic workflows bring in risk scenarios; they not only respond, but they also act. When the autonomy is too great, a discount lets the agent go ahead with actions of consequence without being reviewed. It is possible for recursive actions to become recursive when an agent calls itself and/or loops over a task. It is possible that Tool chaining vulnerabilities occur when the output from the first tool is fed directly into the second tool, but legitimate input data is embedded in the output of the first, without adequate attention. Unauthorized execution paths are the term used for the paths that an agent discovers to a capability that it was not supposed to know. Most often, they are a combination of tools that are combined in ways that the agent wasn't prepared for.
Shadow AI and Unapproved LLM Usage
Shadow AI is the creation and utilization of tools that do not meet security's approval and are not known to security. Staff enter sensitive data into public chatbots and wire in personal API keys into the workflows and install browser agents to read internal pages. Each of those poses data exposure that the company is unable to account for. The fundamental issue is in the governance blind spot, the fact that models, agents, and tools you don't know cannot be protected. The first step in a strong AI governance approach is to identify this usage, which starts with visibility into infrastructure, cloud, and employee devices. Akto addresses this by automatically identifying APIs, LLMs, AI agents, as well as MCP tools in an environment, even those in employees' laptops, and making them visible.
Major Types of AI Security Vulnerabilities
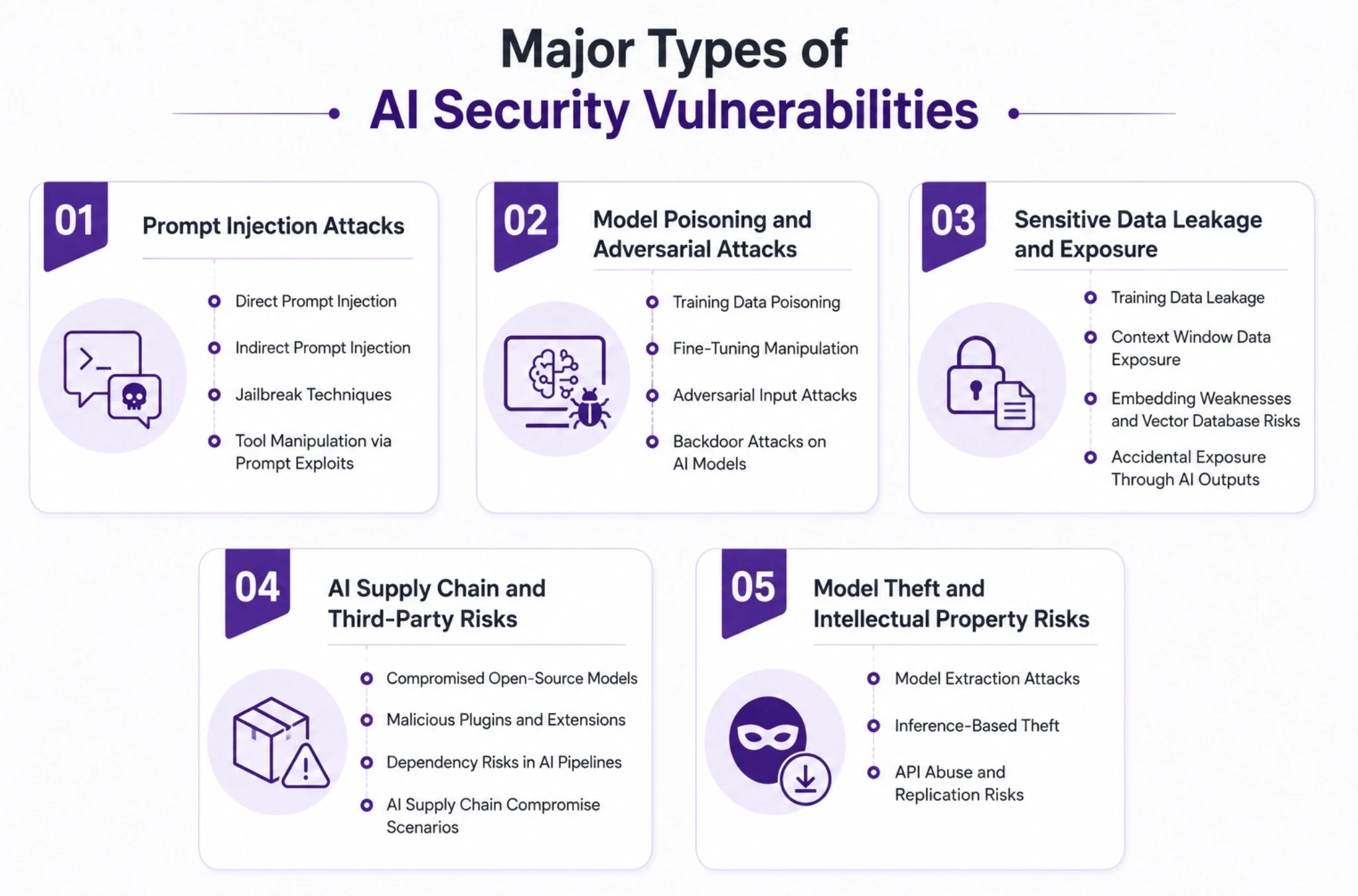
Prompt Injection Attacks
Prompt injection refers to the process of tricking an AI system into performing an action by inputting a carefully formulated prompt. DPI (direct prompt injection): Adversarial text enters the model directly from the user. An indirect prompt injection involves writing instructions within content that the model subsequently reads, such as a web page, document, or email that the agent fetches for the model. Jailbreak techniques are used to bypass rules on safety, using role play, encoding, or step-by-step framing. A dangerous case for agents is being able to manipulate the tool via prompt exploitation—injecting an instruction to an agent that causes it to use a tool or API that the model was never meant to use. Effective guardrails monitor what is placed in the model, AND what it attempts to do, not just the prompt.
Model Poisoning and Adversarial Attacks
A model is corrupted by means of its data or training; during this process, it is called poisoning. Poisoning is done by planting malicious and biased examples in the training set, and the final product will follow the instructions given by the attacker under specific events. Later, in a manipulation fine-tuning stage, also a tuning, this is done on a smaller, less observed data set. Subversive attacks are designed to provide inputs that are also normal to human eyes but will always lead to an incorrect or negative output in the model. During normal testing, backdoor attacks can remain dormant and only activate specific behavior at the time the attacker chooses when the specific pattern occurs.
Sensitive Data Leakage and Exposure
AI systems can have multiple types of data leakage that affect their performance. A model reproducing the sensitive information that it has learned during the training process is referred to as training data leakage. The data exposure in a context window occurs when data from one user remains and appears in another context window or response. The other threat that is less salient is embedding weaknesses: embedding vectors for retrieval can be reversed and queried to retrieve the content behind the embedding, so a vector database becomes a copy of your sensitive data. It's completed with accidental exposure via AI outputs, where a piece of the AI's secret, credentials, or personal record gets included in the response simply because it popped up somewhere in the context.
AI Supply Chain and Third-Party Risks
Parts that you didn't build are used in AI systems. Open-source models that are compromised may be loaded with backdoors or bad behavior that are installed prior to your download. Malicious plugins and extensions ask for a wide range of permissions, and misuse them when they are connected. AI pipelines face dependency risks like classic software supply chain problems, including poisoned packages and the unconfirmed authenticity of AI model weights. The compromise of the AI supply chain can then take place – potentially very far upstream, as in a public model hub or popular tool – without your own line of code being targeted.
Model Theft and Intellectual Property Risks
Internet model theft is aimed at a valuable piece of intellectual property—a trained model. In model extraction attacks, they query an exposed model extensively enough to learn it to create a copy that’s similar to the original. Inference-based theft reconstructs proprietary behavior or data based on outputs. Unrestricted or poorly protected model endpoints are a source of API abuse and replication risk because an attacker can take enough responses to clone the capability and/or run up a cost. This exposure is minimized through rate controls, authentication, and usage monitoring for model APIs.
LLM Application Vulnerabilities in Real-World Environments
Wherever you see a model in a production system, LLM application vulnerabilities will appear. One attack can get a lot of juice, especially when Enterprise LLM applications have access to internal data and tools that are broad. Customer-facing AI assistants have designed themselves to be untouchable and extract data, and this is where they can be easily targeted for data extraction, or “jailbreaks.” Multi-Agent Security failures are when a compromised agent or a confused agent transmits bad instructions to other agents in the chain. Retrieval-augmented generation poses risks because of two sources: poisoned documents in the knowledge base are believed as context, and the model treats stuff in the knowledge base as facts. In autonomous systems, runtime risks are the most pronounced, due to the fact that this model is operating on these inputs in real-time, making calls and altering state prior to someone looking at the decision.
Real-World Impact of AI Security Breaches
Typically, AI security incidents occur without any bells and whistles. When an attacker is able to find an input the model cannot cope with, reads or triggers an action from the model, scales it up before anyone can see the pattern, they have succeeded. A common objective that the attacker is trying to obtain is to manipulate business logic, such as having the system approve a 'refund,' a 'change,' or other actions that the system should not take. Personal and regulated data are not without compliance and regulatory liability, and these events expose them to that risk when the personal and regulated data leaks. A financial and reputation blow occurs when the customer-facing assistant(s) leak or act incorrectly. Falling out of the supply chain introduces 3rd party risk – failure of a shared model or tool impacts all companies that use it. All these outcomes put together are what now present the risks of AI cybersecurity and GenAI security as a risk in enterprise risk registers and not just in research papers.
How to Mitigate AI Security Vulnerabilities?
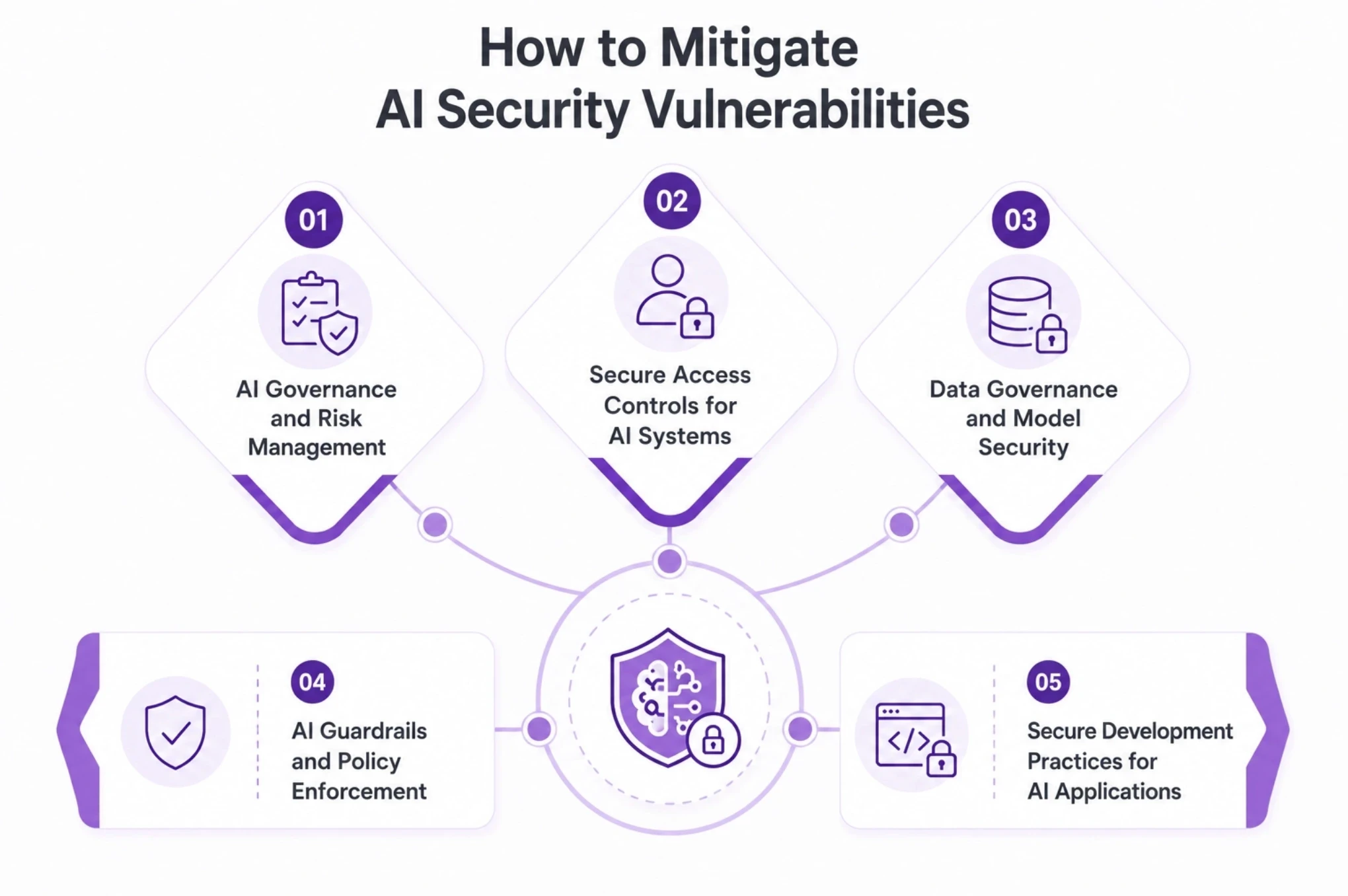
AI Governance and Risk Management
AI governance provides the structure for the program. It specifies the models and agents that are authorized to be deployed, ownership of these models and agents, data that they are allowed to manipulate, and the method of quantifying risk before deployment. Getting a proper inventory is key to good governance, as only what you see within a system is covered by a policy.
Secure Access Controls for AI Systems
Treat each model and agent as an individual and with the least privilege. Implement the scope of what each agent can call, separate read and write access to models and tools, and use very strong authentication (as opposed to weak) for model and tool access endpoints so that the bog pain in a compromised agent cannot call out of scope from the task.
Data Governance and Model Security
Manage inputs to training, tuning, and context. Filter out or obscure fields before they get embedded into a model, limit what's embedded into vector stores, and monitor the lineage of the data used by the model, which would be information the model could ingest again.
AI Guardrails and Policy Enforcement
The guardrails are rules at the input and output boundary: They filter what gets added to the input; They block dangerous answers; They limit what an agent can do in its response. Ideally, there should be a policy that adjoins the system, rather than a single-off configuration.
Secure Development Practices for AI Applications
Integrate AI into established safe application practices. Pre-coding reviews, pre-threat-model workflow of the agent, prior to run, and pre-testing AI components in the build pipeline to identify vulnerabilities prior to delivery.
Continuous Security Testing for AI Systems
Why Continuous Security Testing Is Critical
There's that old saying that a model which passed review last month is going to look different if there's a prompt change, a new tool, or a fine-tune. This ongoing security evaluation is done as the system evolves and is much more suitable for AI than a one-off security evaluation.
AI Red Teaming Best Practices
Red teaming by AI attacks your systems as an adversary! For example, it searches for prompt injections, jailbreaks, data leaks, and improper usage of tools. Rather than once a year, it comes up while they are more easily addressed.
Automated Testing for LLM Applications
Manual tests can't keep up with the rate of change of AI applications. Automated tests run against every change and test for known attack categories to consistently provide coverage at scale. Adopted by Akto for APIs and AI systems, the large library of pre-built security tests includes OWASP Top 10 and business logic weaknesses, and can be complemented with custom tests, and can be integrated into CI/CD so checks are conducted during each build. Akto received a Representative Vendor Industry Marketer Status in the 2024 Gartner Market Guide for API Protection.
Behavioral Monitoring and Threat Detection
There is a difference between testing for weakness and behavioral monitoring for abuse, and that is that behavioral monitoring comes after testing for weakness has identified it. By observing the behavior of models and agents in the real production, such anomalies, misconfigurations, and attack patterns can be detected that are not identified by static checks.
Runtime Protection for AI Systems
Blocking Prompt Injection in Real Time
An on-road runtime protection allows the live traffic and agent behavior to be checked, and any suspicious traffic and actions are therefore detected "on-the-fly," rather than later through log review. Runtime Guardrails decrease the likelihood that an injected instruction would get to a tool or API.
Detecting Malicious Agent Behavior
If an agent tries to use a tool that it is not used to, or if it tries to access information that it does not typically access, then that is a flag. When you're able to see that behavior running, from that signal, you create a detection.
Preventing Unauthorized Tool Usage
Runtime tool and API enforcement prevent an agent from attempting to use its tool and API, even if it was maliciously prompted to do so, but never actually authorized to use it.
Monitoring Autonomous Actions
All autonomous systems should be visible. How much each action an agent takes is logged and monitored, providing teams with a history to review and informing them of alerts. Akto offers runtime protection and threat detection for APIs and AI systems, ensuring visibility into their activities in production.
Securing Agentic AI Systems
Protecting Autonomous AI Agents
Getting agentic AI begins with the information you'll need to know about all of the agents that are available and what they can reach. It is from there that protection involves restricting actions, confirming what is entered in the world, and observing what an agent does in the world, as this is an agent that does something in the world that has to be protected, while a model only answers, but does not.
Managing Permissions and Tool Access
Indicate to each agent only the tools and scopes he or she needs in order to be able to do that work and keep checking the lists. Possibly one of the biggest attack surfaces an AI agent has is overbroad tool access.
Securing Multi-Agent Architectures
If agents share the work amongst each other, the trust they have between them becomes an ignored part of the attack surface. Ensure that messages are passed between agents and do not become trusted commands transmitted from one agent to another.
Human-in-the-Loop Controls
When really big actions are needed, remember to NOT just leave a person out of the decision. The agent has limited control of changing access to move money, delete data, etc., and can only do so if approved. Damage only has to be done if the agent is approved to move money, delete data, or change access limits to it.
Runtime Visibility Across Agentic Workflows
Agentic workflows can only be secured if you can see them. No gaps are left open from agents, tools, and connections, thanks to the continuous discovery and runtime visibility. Akto maps AI agents and MCP tools on infrastructure, cloud, and employee devices, conducts continuous red teaming, and manages the posture of agents, allowing teams to view and manage how these agents are working.
Future AI Security Challenges in 2026 and Beyond
Emerging threats are going to replicate with the advance of more capable, more connected agents. The cost of a single manipulated step rises with autonomy, which is used to guide decision making, and increases as systems are entrusted with higher and higher levels of autonomy and become less and less subject to human oversight. The prospects of gaining ownership of new tools, modalities, and memory in generative AI models will continue to grow, and with that, the size of what the attacker is able to influence in these models will grow. Documentation and evidence of controls will become more important as the responsibilities for AI compliance and regulation become clearer in the future, in relation to how it must be tested, how it must be presented "transparently," and how handling and safeguarding data will be done. For AI attacks of the next generation, you'll need to invest now in discovery, ongoing testing, and runtime controls – otherwise, you will fail to keep up with the systems. These changes will continue to ensure that AI poses a significant risk to businesses' security.
AI Security Best Practices Checklist
Essential steps to reduce AI security vulnerabilities:
Inventory all AI assets and agents, including shadow AI in use across teams
Restrict access to sensitive tools and APIs with least privilege
Implement runtime protection controls for models and agents
Conduct continuous AI red teaming rather than one-off assessments
Monitor for prompt injection attempts at input and output
Secure vector databases and embeddings against inversion and leakage
Validate third-party AI dependencies and model sources
Enforce AI governance policies with clear ownership
Test agentic workflows continuously as they change
Final Thoughts on AI Security Vulnerabilities
AI security risks have become a permanent part of the enterprise risk matrix, and no longer a byproduct of their early adoption. Systems that generate real value, systems that are customer assistants, coding copilots, and even autonomous agents are the same systems that unlock new avenues in 'prompts, tools, data, and model behavior'. Security as an ongoing task is a resilient strategy - it inventories all models and agents, triples the number of restricted ports they are able to reach, constantly tests them, and monitors their run-time behaviors. As agentic AI is making more decisions, these controls must continue to be implemented on an ongoing basis, and they must keep up, or else they lag behind those of systems that adapt.
This is the case for Akto. Its platform finds your APIs, LLMs, AI agents, and MCP tools, performs ongoing security testing, red teaming, posture management, and run-time guardrails. Book AI Agent Security demo of Akto to experience for yourself on your own systems.
Important Links

Experience enterprise-grade Agentic Security solution