What is MCP Security? Understanding Model Context Protocol in AI Systems
Learn what MCP Security is and how Model Context Protocol works in AI systems. Understand its architecture, components, and role in enabling secure AI agent integrations.

Sucharitha

Most security teams are still thinking about AI as a chatbot. But the systems being deployed today have access to your internal tools, the data, and the entire infrastructure.
And the technology that makes all this possible is called the Model Context Protocol or MCP.
MCP acts as a universal connector that lets large language models (LLMs) talk to external tools, databases, and services in a structured way.
MCP is the reason behind your AI agent being able to fetch a Slack message, query the backend, or write custom code. This flexibility makes MCP security one of the most urgent concerns in AI.
In this blog, we answer everything there is to MCP security, from defining key components to framing real attacks and highlighting MCP best practices.
What is MCP Security?
The Model Context Protocol is an open standard that gives LLM agents a structured way to connect to external tools, data sources, and services. Instead of hardcoding every integration, MCP creates a common layer that any agent can use to discover tools, call them, and act on the results.
Definition of MCP Security
MCP security refers to the set of practices, controls, and tools used to protect systems built on the Model Context Protocol from being exploited, misused, or compromised.
Why does it matter?
When you ask an AI assistant to check your calendar, query a database, or push a commit to GitHub, MCP is the layer handling that connection. It defines how the host application, the client, and the server talk to each other, and what actions the agent is allowed to take.
MCP security ensures it covers everything from how servers authenticate incoming requests to whether an agent can be manipulated.
Key Components of MCP Security
MCP security is a combination of overlapping protections that work together across the agent lifecycle. Here are the core components:
Context Handling
The context window is the most powerful and most vulnerable part of any LLM agent. Everything the model sees, it acts on. MCP security requires that what enters the context is validated and trustworthy.
That means sanitizing data retrieved from tools before it is passed back to the model, detecting prompt injection attempts hidden inside returned content, and making sure the agent cannot be manipulated through what it reads.
Tool Access Control
Agents should only be able to reach the tools they genuinely need for the task at hand. That means, defining exactly which tools each agent can call, what parameters those tools accept, and under what conditions they can be invoked.
Identity and Session Management
Every request flowing through MCP should be tied to a verified identity. This helps enforce proper authentication at the server level, using short-lived tokens instead of long-lived static secrets, and making sure sessions cannot be hijacked or replayed.
How MCP Security Fits into AI Security Platforms
An AI security platform needs to be aware of MCP traffic specifically. It needs to know which tools are being called, what data is flowing through them, whether the behavior matches what is expected, and whether anything in the interaction looks anomalous.
Because generic network monitoring will not catch a prompt injection, and generic access controls will not stop an agent from being manipulated into calling a tool.
This is why MCP monitoring and mitigation need to be first-class concerns, not afterthoughts bolted onto existing infrastructure.
Teams building on LLM agents need security tooling that understands agent context, tracks tool usage patterns, surfaces unexpected behavior in real time, and gives security teams the auditability to backtrack issues.
Why MCP Security Matters in Agentic AI
Although every security program has a threat model in place, most of them were not written with autonomous AI agents in mind.
MCP went from specification to critical enterprise infrastructure in under twelve months.
Security programs take longer than that to update. But there are significant gaps between adoption and security maturity that needs addressing.
Expansion of Attack Surface in Agentic Workflows
A single AI agent using MCP does not just connect to one system. It connects to many, often in sequence.
In traditional software, an attacker who compromises one integration compromises that integration. In an agentic workflow, one compromised step can redirect every step that follows.
An agent that retrieves a malicious document may carry corrupted instructions until the final action, whether that is sending an email, writing to a database, or triggering a deployment.
The attack surface in agentic workflows is not just wide but also dynamic. That means tools being discovered at runtime, servers updated without notice, and so on.
Risks in LLM Application Security
LLM agent security used to mean prompt injection and jailbreaks alone. But MCP changes the risk profile entirely.
When an LLM is connected to tools through MCP, it is an agent taking real actions in the real world. It can read files, call services with credentials it was trusted with, and filter out data through a tool it was designated access for a different reason.
The core challenge in LLM application security today is that the three components: the model, the tools, and the workflow create outcomes that none of the individual components would have caused due to a lack of proper security controls.
The risks compound further when you factor in how LLM applications are actually built. Developers pull in community MCP servers, many of which have never been audited.
Business Impact of MCP Exploits
Although technical risks are quite serious, business consequences make MCP security a must-have control:
Data leakage: An agent with access to internal tools, databases, and file systems can be manipulated into retrieving and transmitting sensitive data without any obvious sign that something went wrong.
Unauthorized actions: MCP agents do not just read things. They write, delete, send, deploy, and trigger. An attacker who can redirect an agent mid-workflow can cause damage that is difficult to reverse and even harder to attribute.
Compliance and governance risk: AI governance frameworks like NIST AI RMF and ISO 42001 are still catching up to agentic AI. As MCP adoption grows across community servers and major platforms, organizations encounter threats that existing AI governance frameworks do not yet cover in detail.
Core MCP Security Risks and Real-World Attack Vectors
Five attack vectors your security team needs to understand before any MCP-connected agent goes into production:
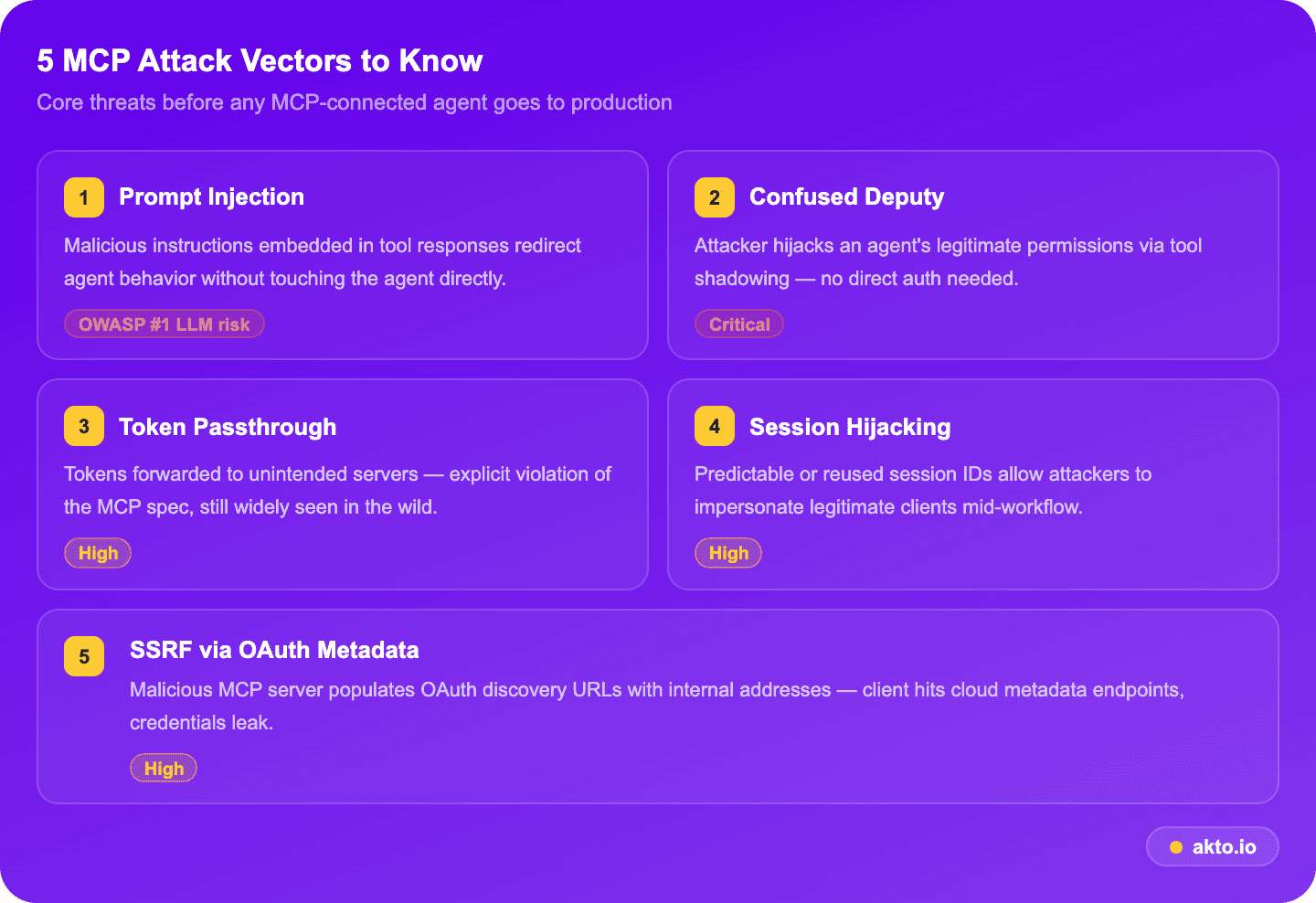
1. Prompt Injection and Prompt Injection Defense
Prompt injection is ranked the number one vulnerability in OWASP's Top 10 for LLM Applications, and in the context of MCP, it is significantly more dangerous than it sounds.
There are two forms of this attack:
Direct prompt injection means the attacker sends malicious instructions through a visible input channel. In an MCP deployment, this could be a user prompt that contains override instructions targeting the tools the agent has access to.
Indirect prompt injection is harder to detect and far more dangerous at scale. The attacker never touches the agent directly. They poison the content that the agent will later retrieve. For example, a GitHub issue, a document in a shared drive, or an email in a connected inbox. When the agent processes that content, the hidden instructions execute.
Prompt injection defense requires layers and not just a single control.
Telling your agent to ignore external commands does not prevent it from following them. The mitigations that actually work are input validation at the tool boundary, context isolation between trusted and untrusted data, output verification before any action is taken, and continuous runtime monitoring to catch anomalous agent behavior.
2. Confused Deputy and Authorization Failures
Confused deputy is one of the oldest problems where a program with legitimate authority is tricked into using that authority on behalf of someone who does not have it.
In the MCP context, the agent is the deputy. It has permissions to call tools, access data, and take actions on behalf of the user. An attacker who can manipulate what the agent does gets to borrow all of that authority without ever authenticating directly.
When an MCP server is launched locally via STDIO transport, any tool the server exposes runs with the same privileges as the user or application that launched it. A malicious MCP server does not need to break isolation. It already operates inside the trusted boundary.
In agentic AI security, the confused deputy problem shows up in several forms. Tool shadowing is one of the most insidious: a malicious MCP server, connected alongside trusted ones, overrides or intercepts calls meant for legitimate tools.
3. Token Passthrough
Token passthrough is a specific class of vulnerability that the MCP specification prohibits, and yet it remains one of the most common authentication failures.
In a properly secured MCP deployment, every token must be validated directly by the server that receives it. The server checks whether the token was issued specifically for it, against the authorization server that issued it. Token passthrough is when that validation step is skipped and a token intended for one server is simply forwarded to another.
The MCP specification explicitly forbids token passthrough. Every MCP server must validate tokens directly against the authorization server, and tokens must never be forwarded or relayed through intermediaries.
4. Session Hijacking and Impersonation
Session hijacking in MCP exploits a specific implementation detail - the session ID. Session IDs determine where the MCP server routes its responses. An attacker can obtain a valid session ID and use it to impersonate a legitimate client.
This could happen if session IDs are predictable, reused, or not cryptographically secured.
The broader concern for security teams is impersonation at the protocol level. Compromised or malicious MCP servers can inject persistent instructions, manipulate AI responses, and exfiltrate sensitive data.
5. SSRF and External System Exploitation
Server-side request forgery in MCP targets the OAuth metadata discovery process. When an MCP client sets up an OAuth connection, it fetches URLs from the server's authentication headers and authorization metadata.
A malicious MCP server can populate those fields with internal network addresses, tricking the client into making infrastructure requests it was never meant to reach. This gives an attacker the ability to exfiltrate cloud credentials from instance metadata endpoints.
Why Static Security Fails in MCP Environments
Traditional security tools were built for predictable systems, unlike MCP-powered agents. They help make decisions at runtime, chain tool calls dynamically, and act on content they retrieve from sources.

Limitations of Traditional AI Security Solutions
Static analysis cannot catch prompt injection that arrives through a tool response at runtime
Perimeter controls do not see what flows between an agent and an MCP server inside a trusted network
Input validation built for web applications does not account for natural language instructions embedded in retrieved documents
One-time authorization checks at connection setup miss tools that silently change behavior after approval
Existing governance frameworks like NIST AI RMF and ISO 42001 do not yet address the specific risks of agentic MCP deployments in meaningful operational detail
Need for Runtime Protection for AI Agents
Runtime protection for AI agents means having visibility and control while the agent is actually running, not just before or after. This is where most security programs fail.
Every tool call an agent makes should be inspected against expected behavior in real time
Context flowing into the model needs to be monitored for injected instructions before the model acts on them
Agent actions should be compared against a baseline of what that agent is supposed to do, with anomalies surfaced immediately
Runtime controls need to understand agent intent, not just network traffic
Human-in-the-loop checkpoints should be enforced for high-risk or irreversible actions before the agent executes them
Key Signals for MCP Security Monitoring
Effective MCP monitoring starts with knowing what to watch. These are the signals that matter:

Tool usage Signals:
Unexpected tool calls outside normal workflow patterns
Tools being invoked with unusual parameters or at an unusual frequency
New tools appearing in the agent's toolset without a change record
Context and Log Signals
Sudden changes in tool descriptions between sessions
Instruction-like content appearing in data retrieved from external sources
Agents querying sensitive resources not relevant to the current task
Agent Action Signals
Outbound data transfers initiated by agent workflows
Privilege escalation attempts through chained tool calls
Actions taken after retrieving content from untrusted or external sources
Session and Identity Signals
Session IDs being reused or showing non-random patterns
Authentication attempts from unexpected origins mid-session
Token usage patterns inconsistent with the issuing scope
Automated Detection and AI Red Teaming for MCP
Agents make hundreds of tool calls, chain decisions dynamically, and operate across multiple servers simultaneously.
By the time a human reviews what happened, the window for prevention has long passed.
This is why automated detection and structured red teaming are mandatory additions to an MCP security program.
Automated AI Security Testing for MCP Workflows
Automated AI security testing for MCP means continuously probing your agent workflows the same way an attacker would, before an attacker does.
Static code scanning will not expose a prompt injection vulnerability that only triggers when an agent retrieves a specific type of external content. But automated testing can by replaying tool call sequences to check for unexpected outputs and verifying that authorization controls hold across every tool in a multi-server setup.
The goal is to make security testing a continuous process tied to your deployment pipeline, not a one-time audit.
AI Red Teaming for Agentic Systems
AI red teaming for agentic systems involves structured adversarial simulation specifically designed around how MCP agents fail.
For MCP environments, red teaming means running structured adversarial tests against your actual agent workflows.
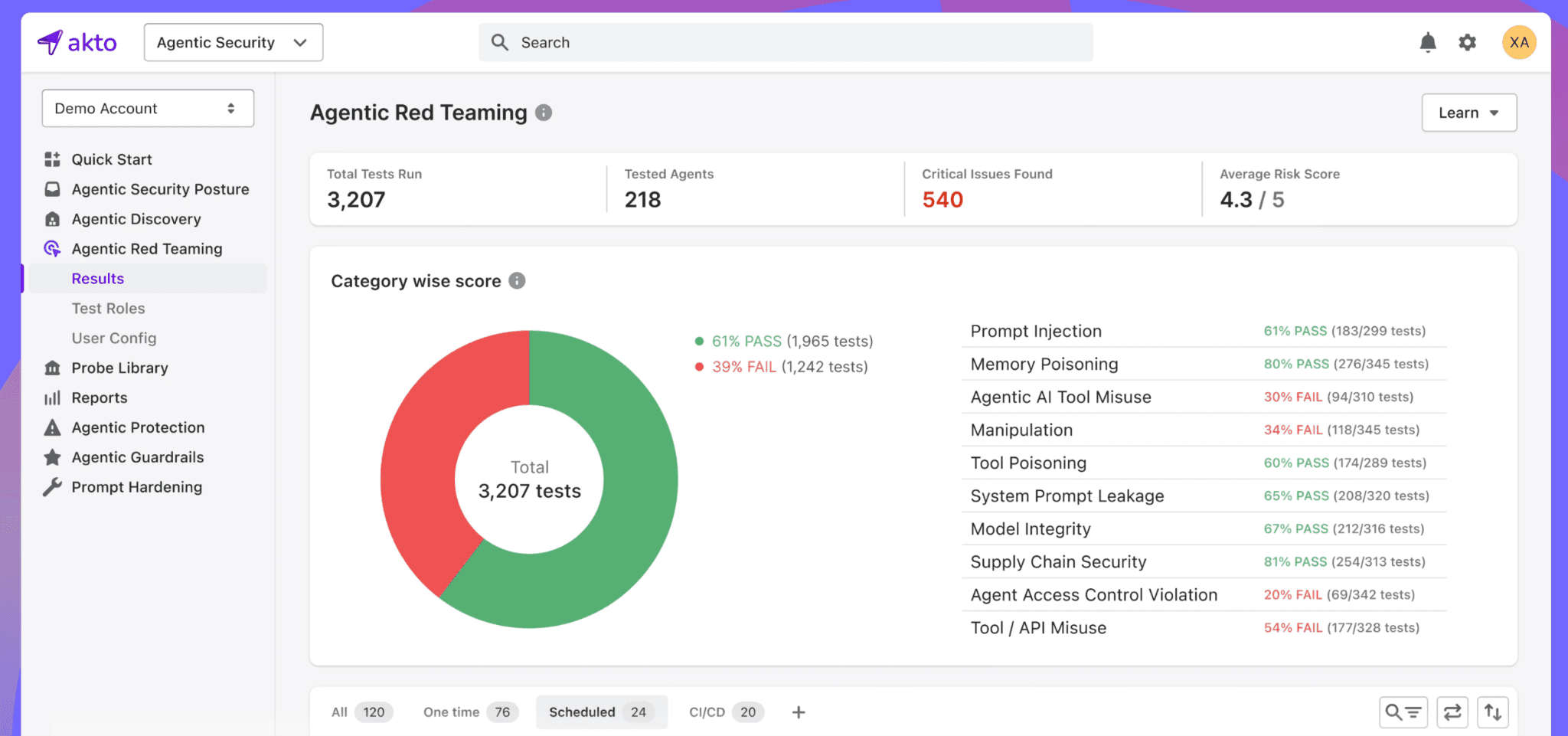
The goal is to find those failure points in a controlled environment rather than discover them through an incident. Red teaming for agentic systems is not a one-time exercise either.
Every time a new MCP server is connected or a tool definition changes, the attack surface shifts, forcing testing to keep pace with it.
Securing the LLM Development Lifecycle
Security cannot be a gate at the end of the pipeline. It needs to be embedded from the starting point of your development cycle.
The popular shift-left terminology applies here.
Shift-left in LLM development means threat modeling MCP connections at the design stage. That is, before a server is connected, or a tool is approved, or an agent workflow is built around it.
Also, MCP environments change constantly and continuous testing is what holds it together. Tools update, new servers get added, and context patterns shift constantly.
Continuous MCP Security with an AI Security Platform (Akto)
Knowing the risks is step one, but having a platform that actively finds, tests, and stops them in production is what actually moves the needle.
Akto is an agentic security platform purpose-built for this era, delivering complete visibility, continuous agentic red teaming, and real-time guardrails to stop agents from wreaking havoc.
Real-Time Monitoring and AI Guardrails
Most security incidents in MCP environments do not look like attacks at the network level. They look like normal agent behavior, pointed in the wrong direction. Catching them requires controls that understand agent context.
Akto's AI guardrails sit between your agents and the tools they invoke, enforcing enterprise policies in real time. Akto analyzes every MCP call, tool usage, execution context, response structure, and parameter pattern to monitor and detect threats as they happen.
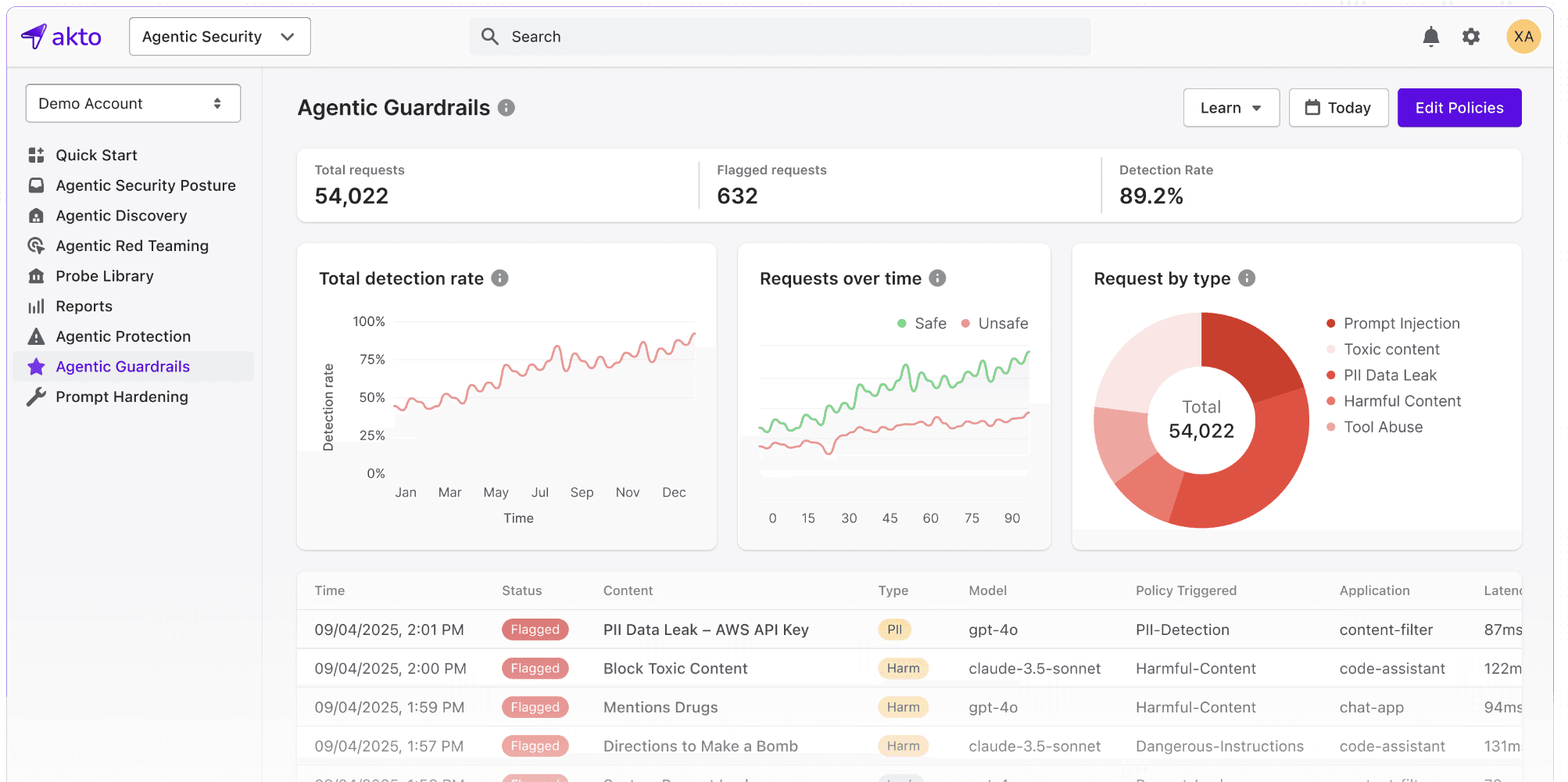
When an agent's behavior deviates from expected patterns, whether it is calling a tool it should not, retrieving data outside the scope of the task, or acting on injected instructions embedded in external content, Akto flags and blocks it before the action completes.
AI Discovery and Posture Management
Most organizations deploying MCP-connected agents today have incomplete visibility into how many MCP servers are running, what tools each agent can access, and what data flows through those connections.
Akto automatically discovers and catalogs MCP servers, AI agents, tools, and resources across cloud infrastructure and employee endpoints, including shadow resources that have never been formally inventoried.
The posture management layer goes further than inventory. It maps agent-to-tool dependencies, surfaces over-permissioned agents, tracks changes to tool definitions between sessions, and gives security teams the lineage visibility to understand exactly what each agent can reach and what it has been doing.
MCP Security Best Practices Checklist
Use this as your baseline before any MCP-connected agent goes into production:

Authentication and Authorization
Enforce OAuth 2.0 on every MCP server
Validate every token at the server that receives it, not just at the entry point
Rotate credentials on a schedule, not when you remember to
Reject any request that cannot be tied to a verified identity
Least Privilege Access
Scope each agent's tool access to exactly what the current task requires
Review and trim permissions every time a new MCP server is added
Treat over-permissioned agents as a misconfiguration, not a convenience
Pin tool versions so silent updates cannot expand what an agent can do
Prompt Validation
Sanitize all content retrieved from external sources before it enters the model context
Treat every tool response as potentially untrusted input
Flag instruction-like content appearing in the data the agent retrieves at runtime
Do not rely on defensive prompts alone
Runtime Monitoring
Log every tool call with full execution context, not just success or failure
Alert on agent behavior that deviates from the expected task scope
Monitor for tool definition changes between sessions
Include shadow AI detection in your monitoring scope to detect blind spots
Incident Response
Build an incident response plan that accounts for autonomous agent behavior specifically
Define what a containment response looks like when an agent
Maintain audit trails that can reconstruct the full agent decision chain post-incident
Test your response plan against agentic attack scenarios
AI Governance and Compliance
Inventory every MCP server and agent connection as a formal organizational asset
Map your MCP security controls to relevant frameworks such as NIST AI RMF and ISO 42001
Define clear accountability for agent actions before deployment
Review third-party and community MCP servers against your supply chain risk policy before connecting them
Future of MCP Security in Agentic AI
MCP reached 97 million downloads within months of release and now has over 1,000 servers in its ecosystem. The security practices have not kept pace with any of that growth, and the gap is evident.
Emerging Threats in Agentic AI Security
MCP vulnerabilities grew 270% from Q2 to Q3 in 2025, with 315 MCP-related vulnerabilities published in 2025 alone
In February 2026, researchers confirmed 1,184 malicious skills across one AI agent marketplace, and 492 MCP servers exposed to the internet with zero authentication
61% of organizations report the use of unsanctioned AI tools, making shadow AI one of the fastest-growing governance gaps in enterprise security
Gartner predicts that by 2026, 75% of API gateway vendors and 50% of iPaaS vendors will have MCP features
Open Source and Research Trends in MCP Security
Here is where things stand:
OWASP released its Top 10 for Agentic Applications in December 2025, peer-reviewed by NIST, Microsoft AI Red Team, and AWS, with Agent Goal Hijack listed as the top threat
The official MCP 2026 roadmap addresses scalable stateless session handling, enterprise authentication with SSO integration, audit trails, gateway behavior standards, and an MCP Server Card format for capability discovery
The signal from the research community is consistent: the vulnerabilities are not exotic. They are basic failures, prompt injection, weak auth, and missing scope controls, applied to a protocol that now has direct access to production systems
Final Thoughts: Securing MCP with Modern AI Security Platforms
The organizations treating MCP security as an ongoing program rather than a one-time audit are the ones that will be positioned to scale agentic AI.
Runtime protection, continuous automated testing, and a unified AI security platform that gives your security team a single view of every agent, tool connection, and action taken are foundational to agentic security.
Akto is purpose-built for agentic AI security, offering features such as automatic MCP discovery, continuous red teaming, and real-time guardrails that address the unique risks of MCP environments.
From automatic MCP discovery and shadow agent detection, to continuous red teaming against 1,000+ real-world agent exploits, to real-time guardrails, Akto gives CISOs the visibility and control that agentic AI deployments require.
Book a demo with Akto and see your MCP attack surface in real time.
Important Links

Experience enterprise-grade Agentic Security solution