Amazon Bedrock Guardrails: Securing Enterprise GenAI Applications and AI Agents
Learn how Amazon Bedrock Guardrails secure GenAI apps with prompt injection defense, PII protection, hallucination control, and runtime safety.

Bhagyashree

As enterprises move towards more limited general availability of GenAI in production, platforms such as Amazon Bedrock have become an integral part for authors harnessing AI to build and scale applications. Teams are using foundation models to build chatbots, automate workflows, and create content for both customer-facing and internal apps.
However, this transition also raises security concerns that traditional controls have not accounted for. Large language models can be attacked through prompt injection; their outputs can be malicious or violate policies, and both may reveal secret data. These are not corner cases-they surface quickly as soon as applications see real user data.
Enter guardrails. No longer can we think of safety considerations as broken glass; we will address this later. Now organizations need AI security controls woven into the generation process-they need guardrails. Guardrails, such as content filtering, measures to prevent model hallucinations, and safeguards against sensitive data leakage, seamlessly integrate these safety considerations directly into the application at runtime.
If this sounds like something you need, look no further than Bedrock Guardrails. Aws Bedrock Guardrails empower development teams to define and implement safety controls within the GenAI application lifecycle. Guardrails substantially reduce the risk of misapplication, help ensure consistent results, and make early deployment safe.
In this Blog, we cover the fundamentals of Aws Bedrock Guardrails, the threats they address, and their role within an overall GenAI security framework.
What are Amazon Bedrock Guardrails?
Amazon Bedrock Guardrails (aka Safety Nets) provide a model-agnostic, pre- and post-generation layer of safety controls that guide safety and privacy rules and responsible AI policies for generative AI applications. The LLM guardrails are a parallel model-evaluation engine with sub-100ms latency that can be integrated directly into user inputs and model outputs.
What Can and Can’t Be Controlled with Bedrock Guardrails?
What can be (and can not be) controlled through the six default guardrail policies? Let's take a quick look at the six default configurations you can set on the Bedrock guardrails, configuring threshold levels (low, medium, high) as needed:
Content filtering (toxicity & harmful outputs): Prevents hate speech, insults, sexual content, violence, and bad behavior in both text and image inputs and outputs.
Prompt Attack Defense: Counters attempts by malicious inputs to override system instructions (prompt injections & jailbreak hacking modes).
Denied Topics (e.g., "investment advice") and Restricted Domains (e.g., "Amazon.com"): Stop the model from discussing topics the user deems inappropriate. Users define topics in natural language, so the system can block topics such as "product comparisons" or "coaching business".
Sensitive Data Detection (PII & Credentials): This feature removes personally identifiable information (such names, addresses, and Social Security numbers) from prompts and outputs.
Word filters (Profane & Competitive): Blocks a list of words or phrases that you don't want to see in the outputs, including bad words or words that are too competitive.
Contextual Grounding & Accuracy:
Contextual grounding: This checks for hallucinations by seeing if the model's output is based on the source material in a certain context.
Automated reasoning: Putting the model's output into logical principles to detect additional lies and hallucinations and do research that has an effect on truthfulness.
Multimodal (image) moderation: Analyses visual content for toxicity.
Feature | Controlled / Supported | Limitations / Not Controlled |
Filtering Granularity | Adjustable thresholds (low, medium, high) for 6+ harmful categories. | Cannot differentiate between nuanced creative writing and malicious intent. |
Scope of Data | Input prompts and output responses. | Cannot control content within a trusted document uploaded to a knowledge base (only the query about it). |
Data Redaction | PII and custom regex in output/input. | May not identify obfuscated or highly unusual PII formats. |
Denied Topics | Defined by topic description/examples. | Can sometimes suffer from false positives if topics overlap. |
Code Specifics | Detects malicious code generation, comments, and PII in code. | Cannot determine if code will break functional requirements (syntax). |
Output Moderation vs Input Filtering
Allow input/output filters to be configured independently:
Input Filtering (aka 'User Prompt'): Filters out malicious inputs(jailbreaks, toxic language) prior to entering the Foundation Model.
Output Moderation (aka 'Model Response'): Checks model outputs to avoid potentially malicious information being exposed to the user.
Key Limitations
No Deep Semantic Comprehension in Sophisticated Prompts: Guardrails mostly rely on keyword filtering and semantic similarity; a byproduct is an unconscious blind spot to the indirect intent of sophisticated jailbreak prompts.
Insufficient Contextual Knowledge in Multi -step Conversations: Guardrails can be imposed on Agents and Knowledge Bases, but judge each turn or step relatively independently; thus, in a long conversation, they may not realize a violation is occurring that is gradually deconstructed over a long-term multi-step back-and-forth, which then violates LLM guardrails being relatively shortsighted.
Limited Preset PII: Preset PII filters are rigorous, but identifying strongly customized or non-standard custom data in general would require numerous custom regex declarations.
How Bedrock Guardrails Protect AI Agents from Prompt Injection, Hallucinations, and Unsafe Actions
Amazon Bedrock Guardrails provides a managed safety enforcement layer that integrates with agentic workflows to promote safe and responsible AI capabilities.
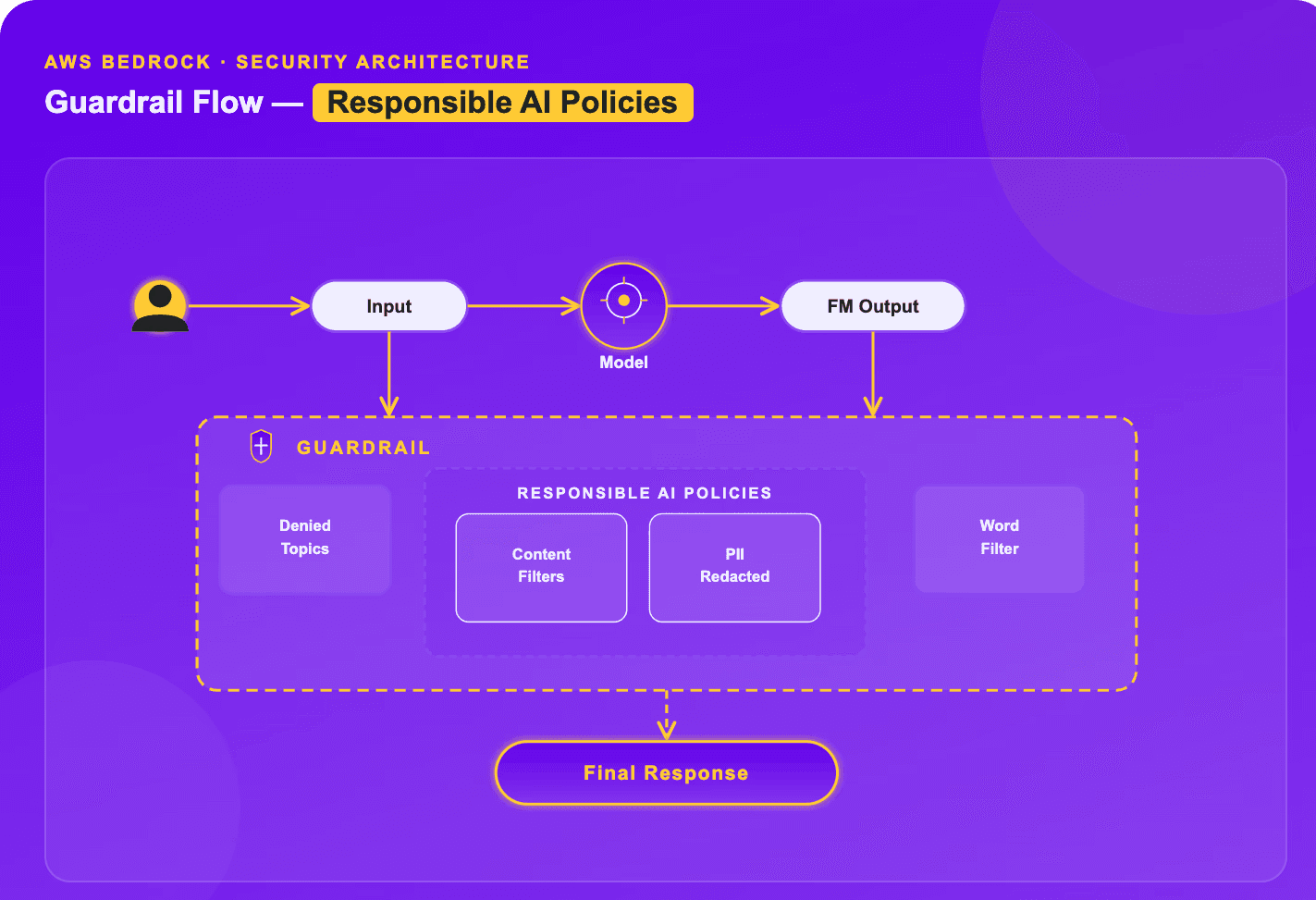
Integration with Agentic Workflows
Agent-wide Policy Enforcement, One safety foundation for all agents: Helps developers enforce uniform safety standards across various agents and code bases without editing individual models directly.
Native integration with Agentic Workflows: Natively integrated with Amazon Bedrock Agents, and can be invoked through API with orchestration stacks like CrewAI or AgentCore calling the Apply Guardrail API.
Protection for Multi-step Agents: A supervisor for multi-step agents that reason over multiple steps (e.g., ReAct), the guardrails stay in place during the cycle, assess the first prompt, then predict the final answer.
Applied Protection Levels
Input Prompt Level: The input prompt stage filters user questions before they are fed into the model. This can cover topic blocking (e.g., jailbreaks), prompt-injection prevention, and content filtering for "denied topics".
Output Response Level: The output response stage prepends and scans the model output before returning it to the user.
This level encompasses PII redaction, harmful content prevention, and contextual grounding tests.
Interaction with APIs, Tools, and Plugins
Tool Filtering: Native Bedrock Agents will also spend some LLM guardrails on user inputs and final outputs. Developers sometimes also incorporate the Apply Guardrail API inside AWS Lambda functions (used by agent action groups) to Filter data coming to or leaving third-party software.
Orchestration Plugins: Enabling customers to route requests through Bedrock Guardrails via a plugin (such as the Kong AI Gateway plugin) can be a part of an established API orchestration workflow.
Challenges in Multi-Agent Environments
Agent-Specific Guardrails: Variability of guardrails for different agents (e.g., stricter topic filtering for a customer-facing bot vs. an internal data parser agent) could entail complex per-agent guardrail management.
Indirect Prompt Injection: A major danger exists when an agent exposes untrusted content (e.g., "summing up" an email or website) that contains embedded instructions to hijack the agent.
Countermeasures:
Tagging: Untrusted data (e.g., tool output) should be categorized as "user input" and passed through prompt-attack filters.
Verification Checks: Articulated in orchestration patterns such as plan-verify-execute (PVE) so that agents present only actions consistent with the initial, verified plan.
How to Configure Amazon Bedrock Guardrails for Secure GenAI Applications
Configuring Amazon Bedrock Guardrails enables real-time content safety validation and PII protection by intercepting both user prompts (input) and model responses (output). This step-by-step guide walks through the process of setting up these safeguards, from defining harmful content to enabling data masking and compliance controls.
Step 1: Create a Guardrail
Navigate to Bedrock: In the AWS Management Console, select Amazon Bedrock.
Start Creation: Choose Guardrails from the left navigation pane and click Create guardrail.
Details: Enter a Name (e.g., Enterprise-Guardrail) and a Description.
Message: Configure the Blocked message that users will see if a request or response is blocked (e.g., "I am sorry, I cannot answer this request").

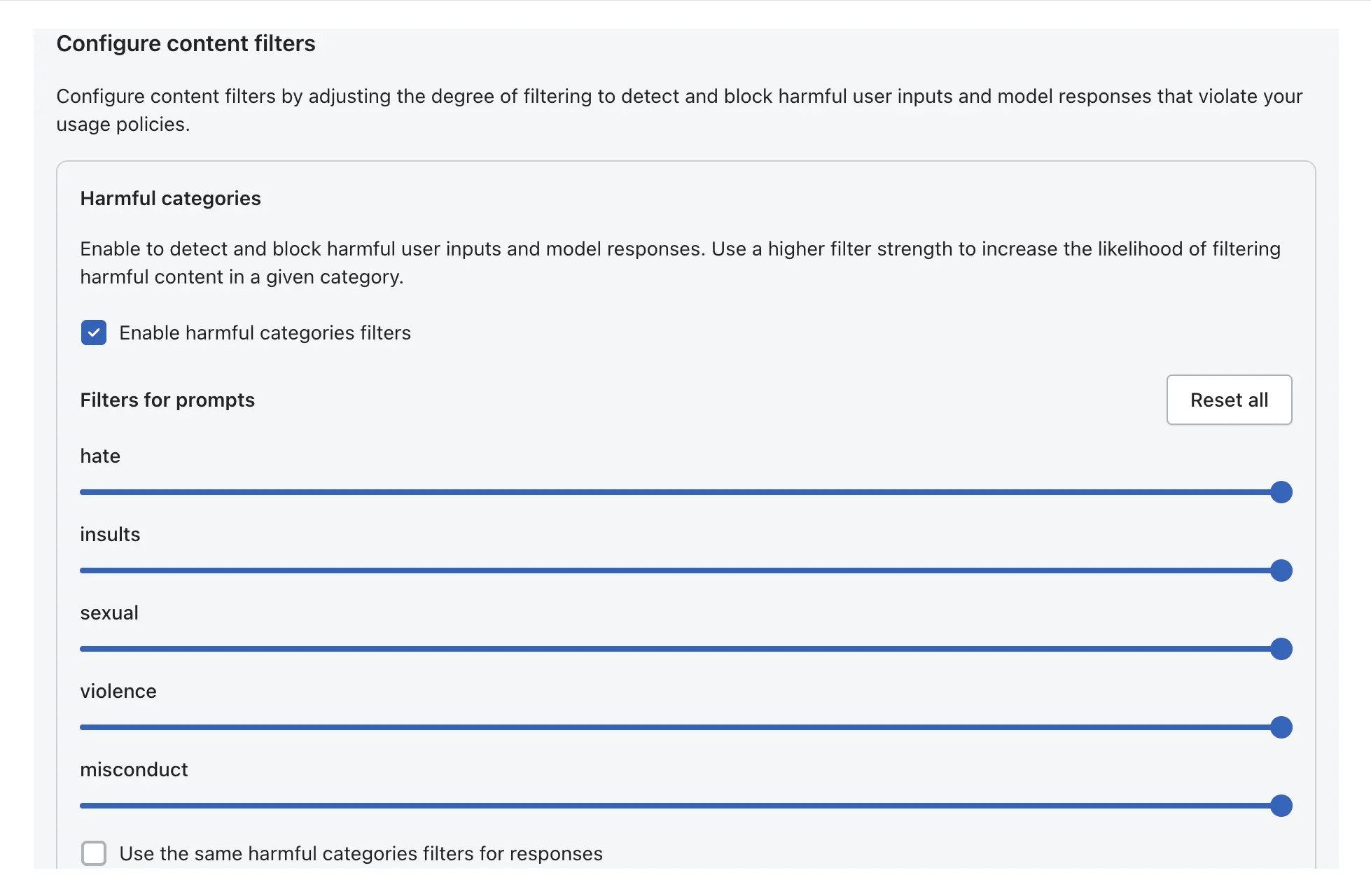
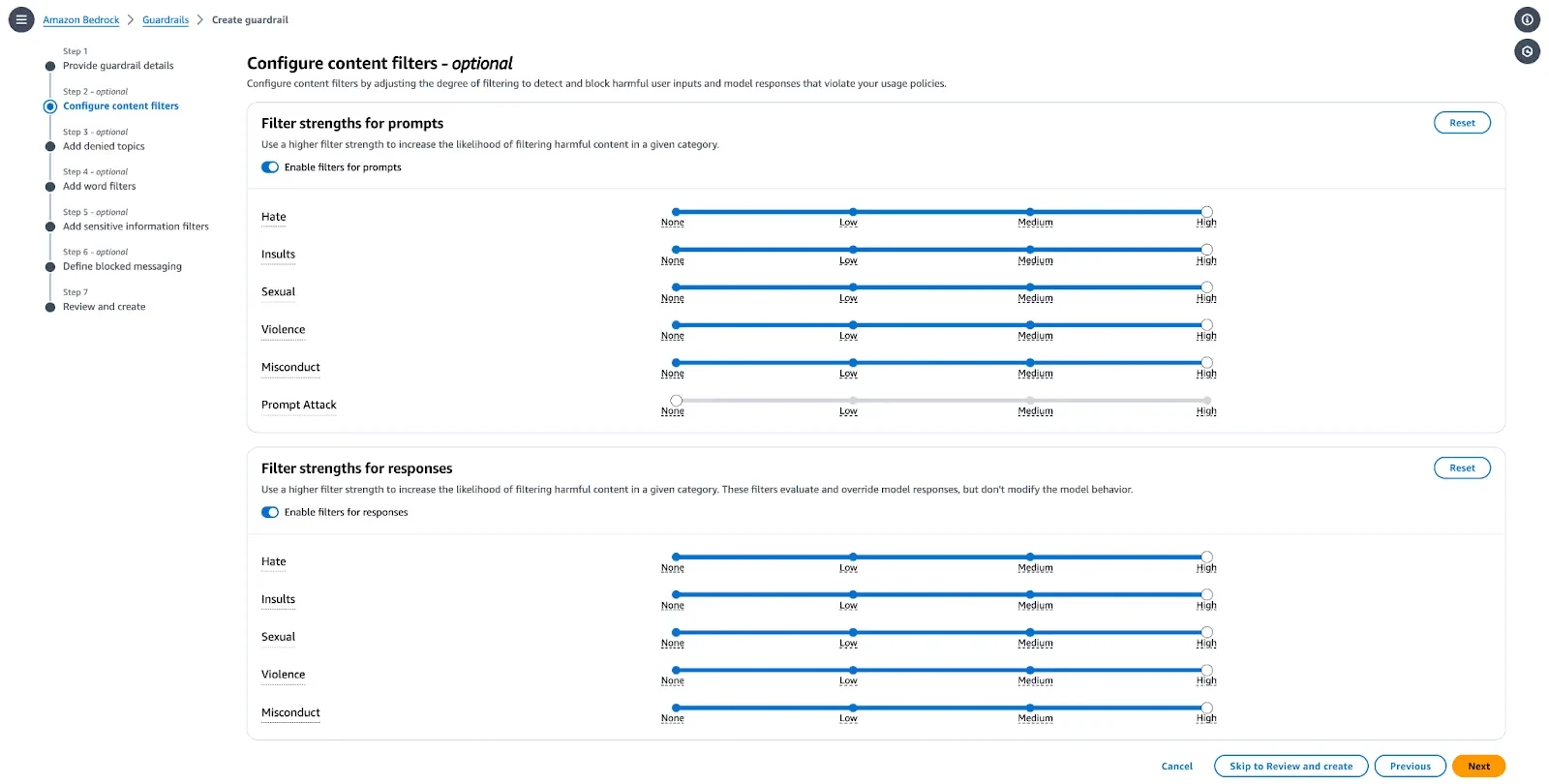
Step 2: Configure Content Filters (Harmful Content)
Define thresholds for blocking harmful content, including hate, insults, sexual content, violence, and misconduct.
Select Categories: Go to Configure content filters.
Adjust Thresholds: Use the sliders to set the threshold for each category from None to High.
High: Most restrictive; blocks everything with even low confidence of being harmful.
Low: Least restrictive; blocks only when highly confident it is harmful.
Prompt Attack Detection: Enable the filter to detect and block prompt injection or jailbreak attempts.
Apply to Text/Images: Set filters for both input prompts and output responses.
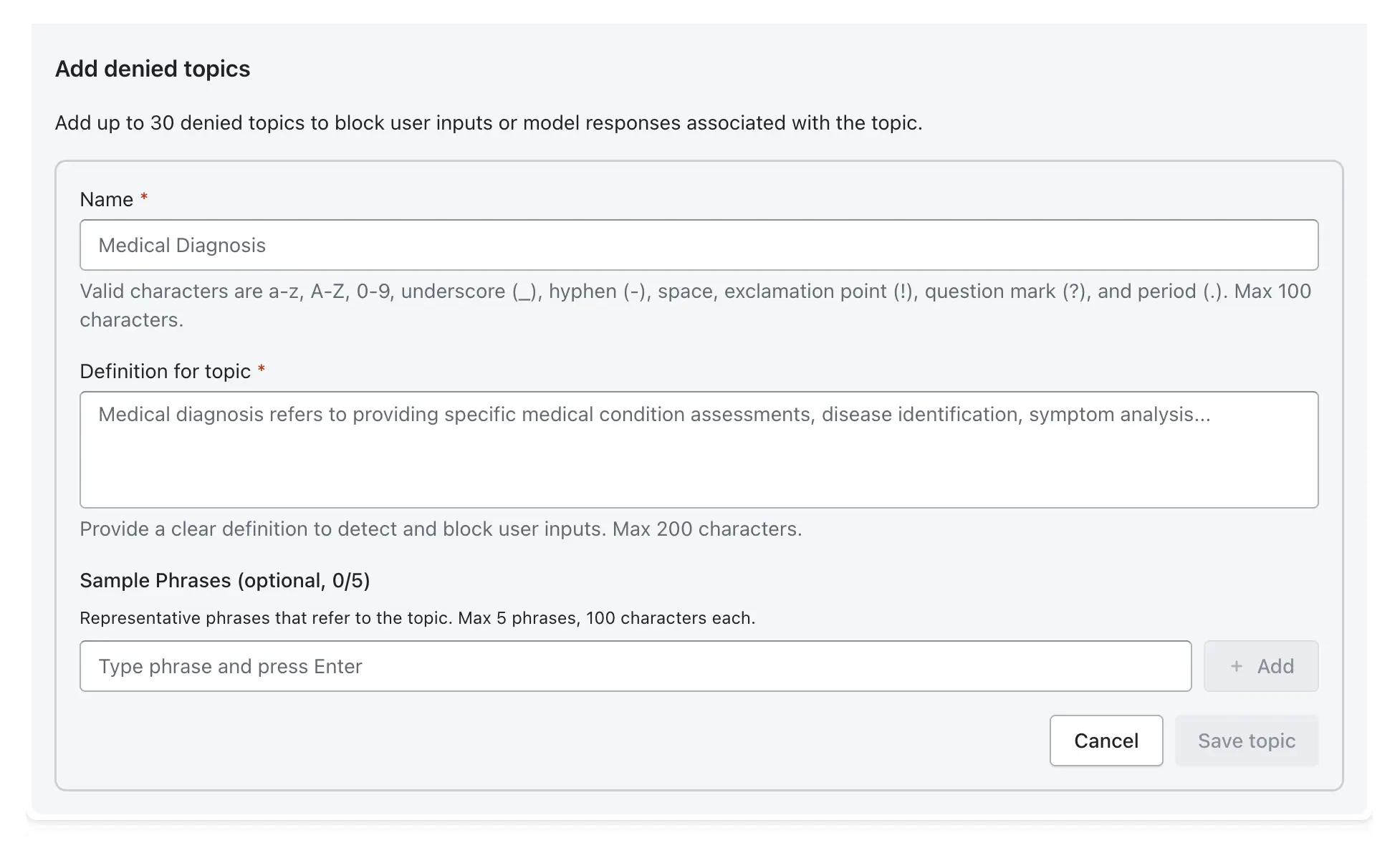
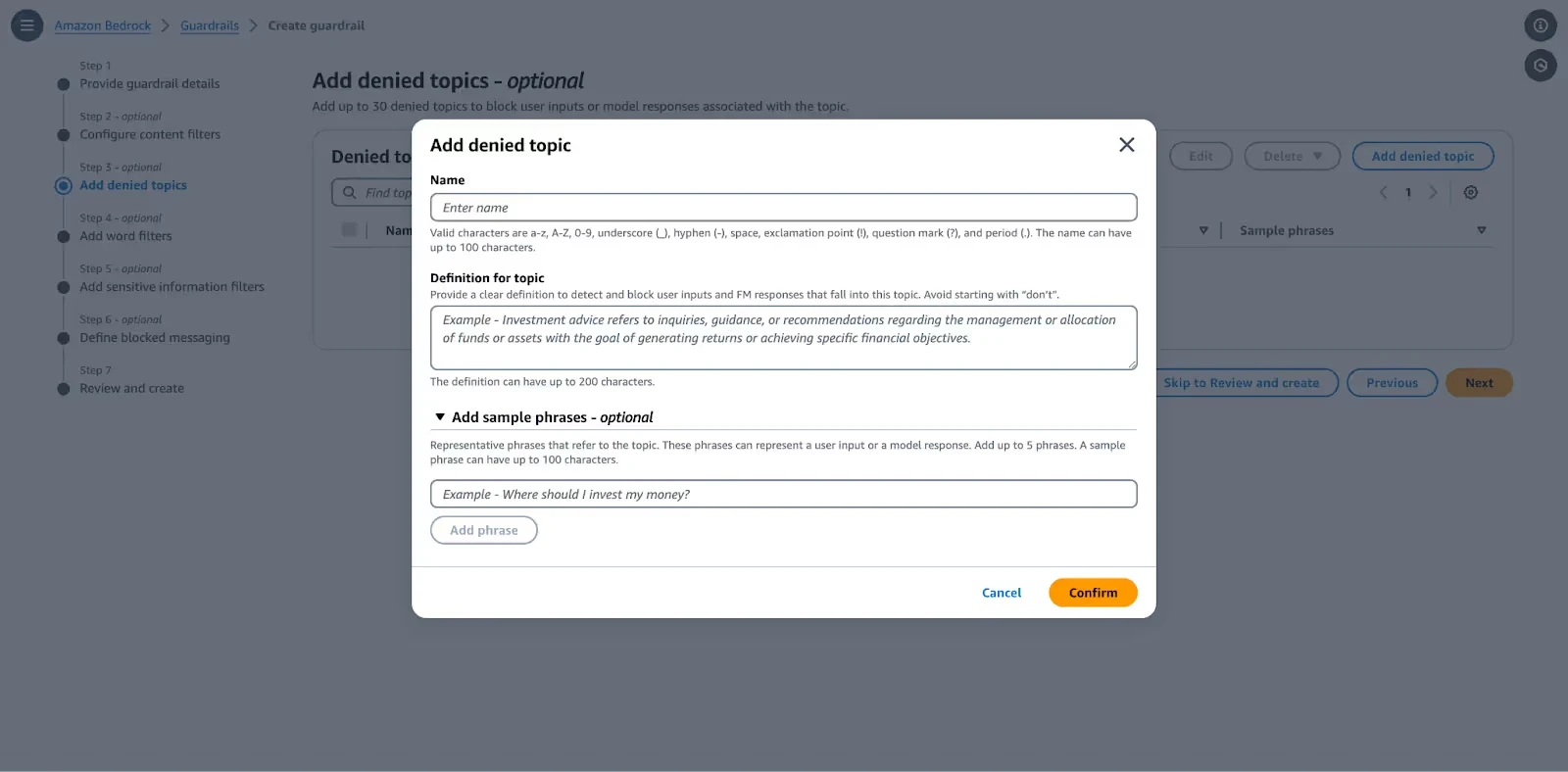
Step 3: Configure Denied Topics
Define specific topics the model should not discuss, in line with business policies (e.g., competitor names, financial advice).
Add Topic: Click Add denied topic.
Name & Definition: Provide a topic name (e.g., CompetitorInfo) and a clear definition of what constitutes this topic.
Sample Phrases: Add sample phrases (e.g., "Tell me about competitor X") to improve detection accuracy.
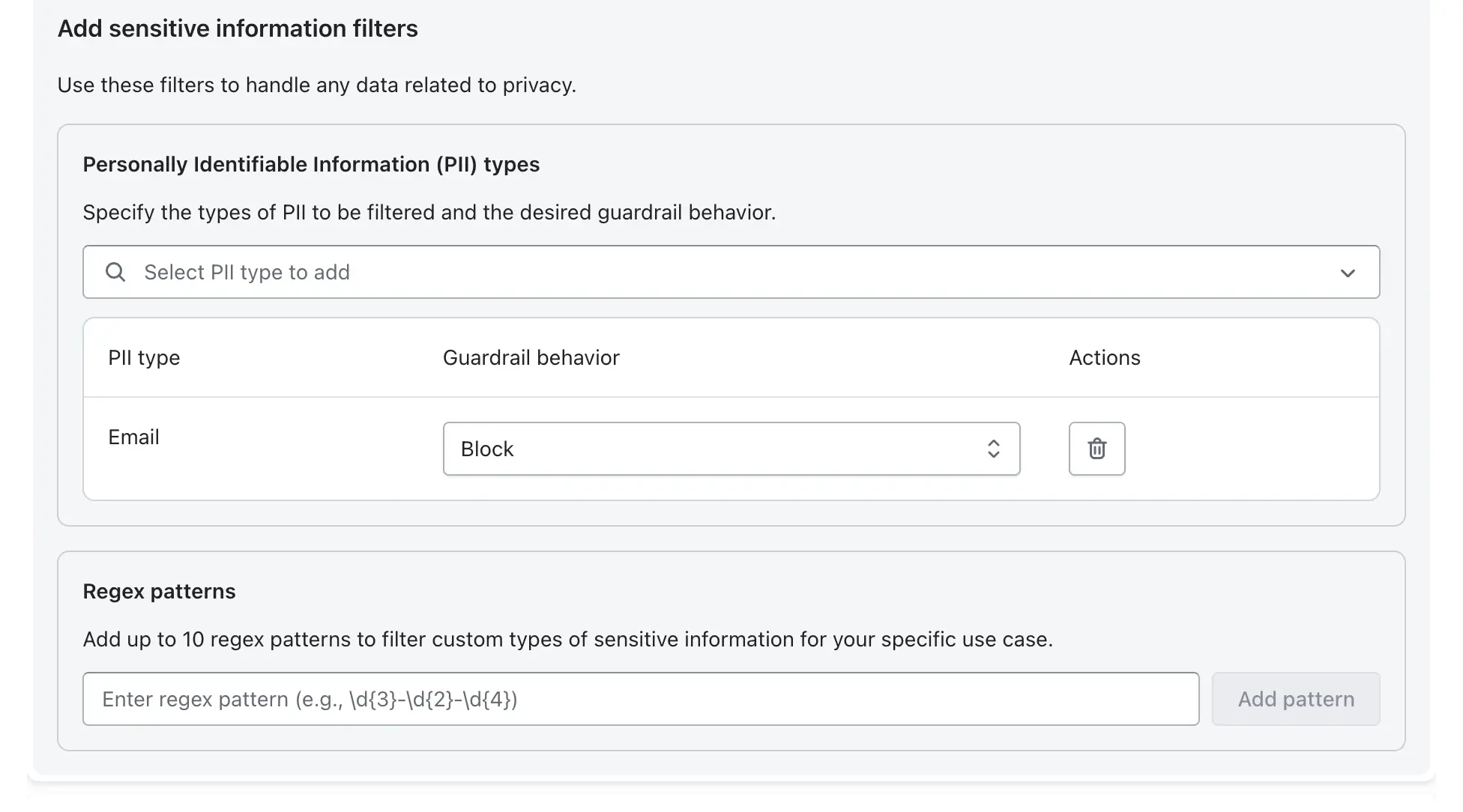
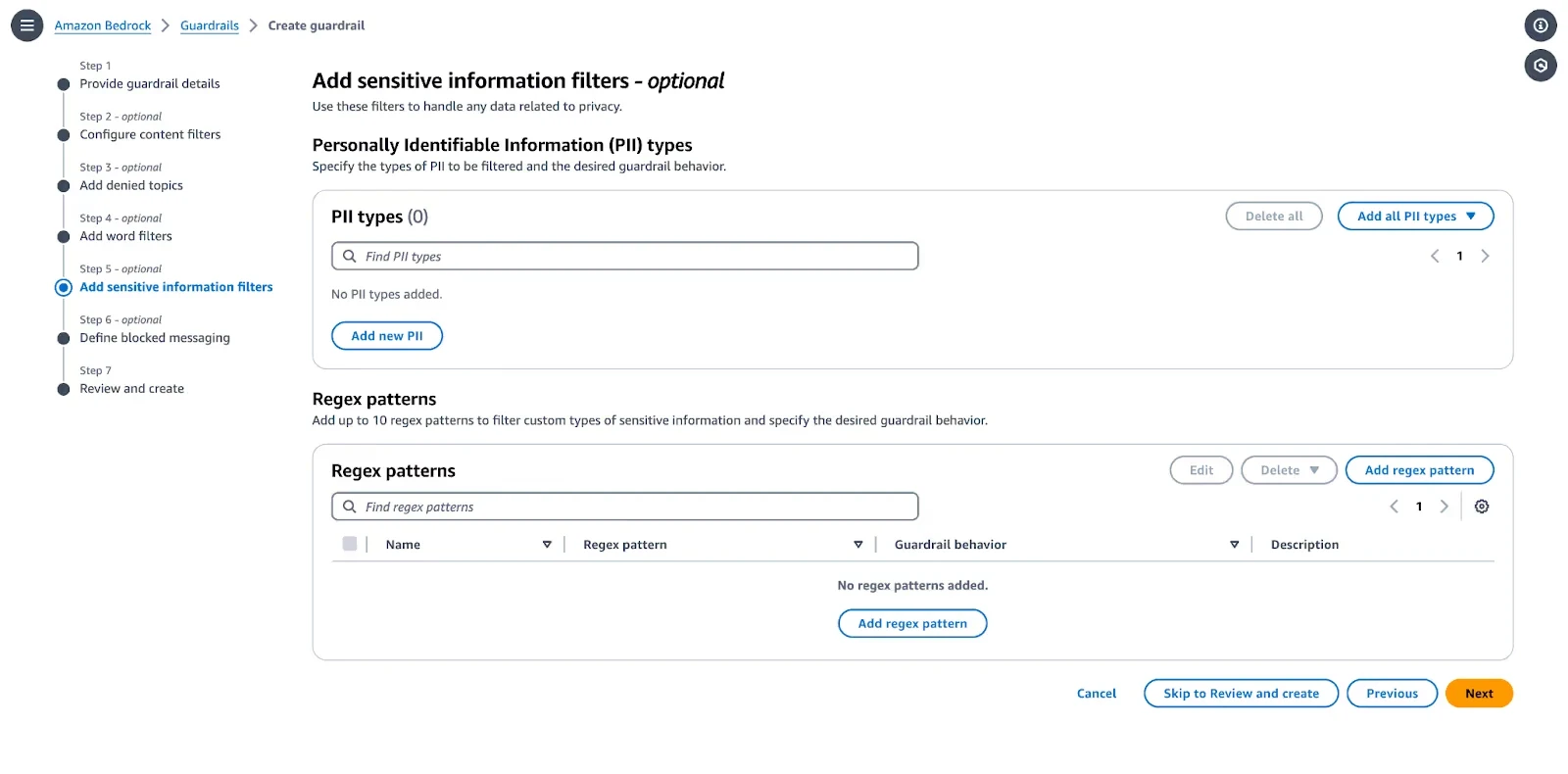
Step 4: Enable PII Detection and Masking
Configure sensitive information filters to handle personally identifiable information (PII).
Select PII Types: Choose the entities to detect (e.g., Email Address, Phone Number, Social Security Number).
Set Action: Choose Block (prevents the message from going through) or Mask (redacts the sensitive data with [PII]).
Custom Regex: Use regex for custom data patterns not covered by default types.
Step 5: Set Thresholds for Blocking vs. Flagging
Bedrock Guardrails operate with a "fail closed" approach by default, blocking content based on confidence scores.
Blocking: If the model's confidence that a query is harmful exceeds the configured threshold (e.g., HIGH), the output is blocked and a block message is returned.
Masking/Redacting: Used for PII to allow the rest of the message to pass while hiding sensitive data.

Step 6: Align Configurations with Compliance (GDPR, SOC2)
To meet regulations, use the following configurations:
PII Masking: Ensures data privacy by addressing GDPR requirements for handling personal data.
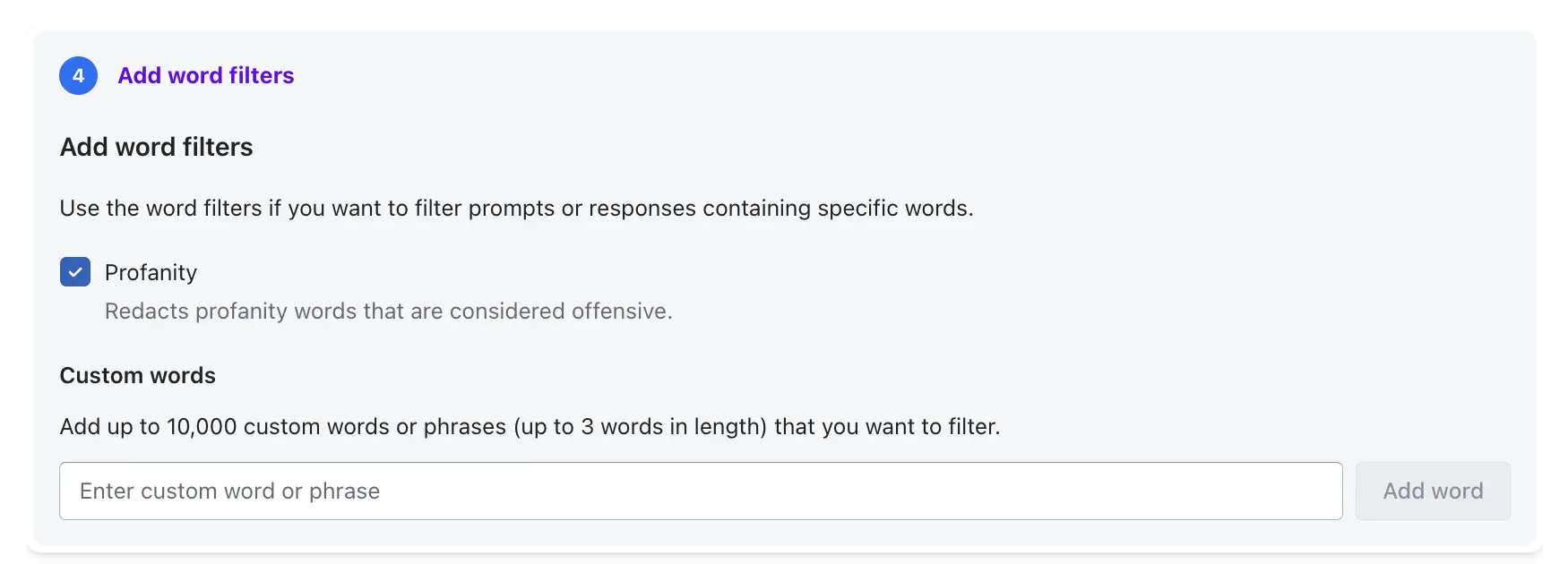
Word Filters: Add specific offensive or non-compliant words to the Word Filters list to ensure compliance with company language policies.
Contextual Grounding: Enable this to detect and block model hallucinations, ensuring outputs are accurate and grounded in provided data.
Audit Logging: Ensure all guardrail actions are logged for audits.
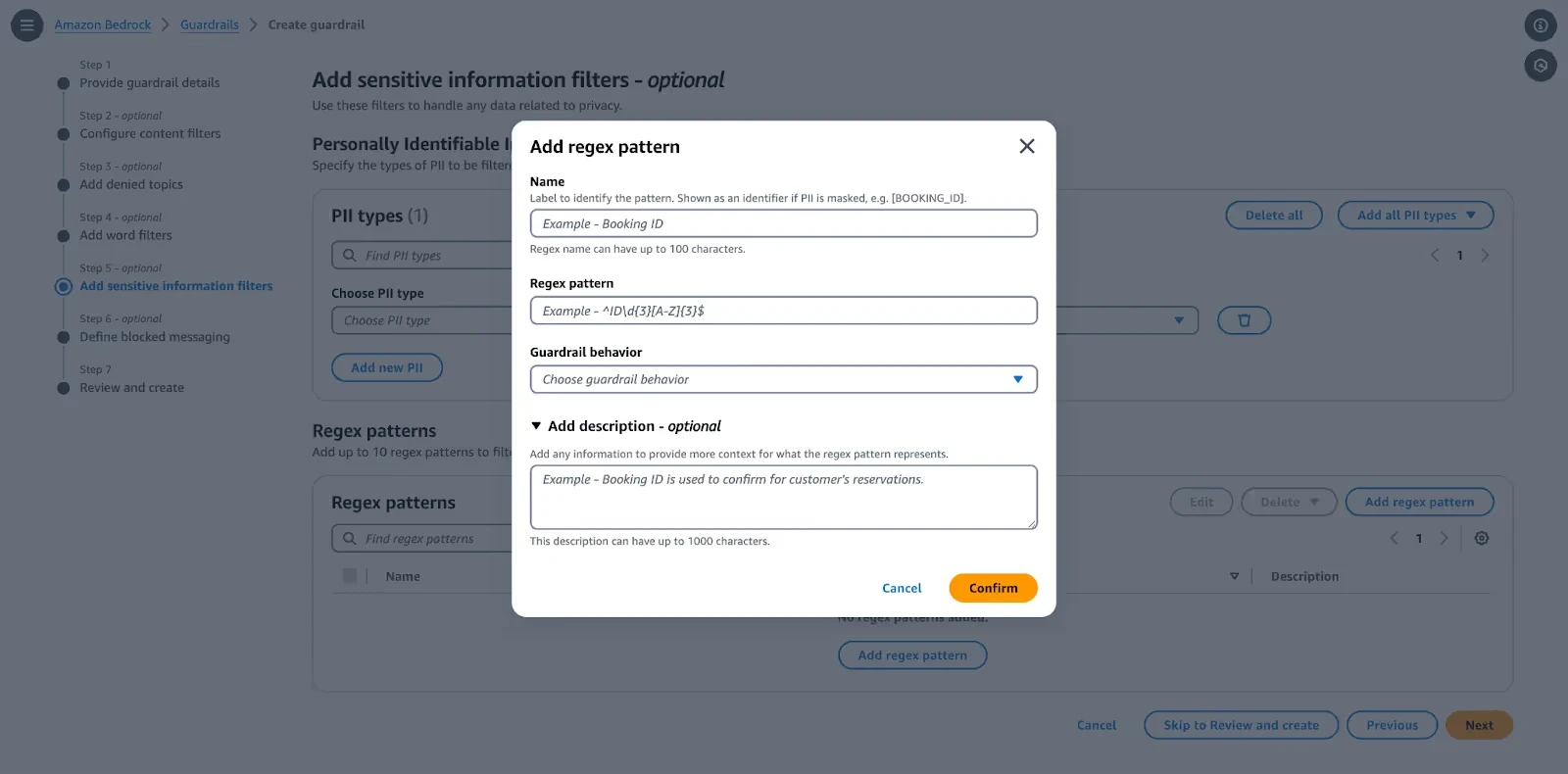
Step 7: Test and Deploy
Test: Use the Test Guardrail panel on the right side of the screen to simulate inputs and verify that your policies block or filter as expected.
Publish: After testing the Draft version, click Create version to create a static, versioned snapshot for production use.
Apply: Attach the guardrail to your Knowledge Base or invoke it directly using the ApplyGuardrail API.
How to Use Amazon Bedrock Guardrails for Contextual Grounding
Implementing contextual grounding and automated reasoning checks involves creating a multi-layered, retrieval-augmented generation (RAG) system that anchors LLM responses in trusted, real-time knowledge sources. By moving away from relying on a model's internal memory toward validating outputs against specific, verifiable data, this approach reduces hallucinations, fabricated, inaccurate, or outdated responses, and ensures factual consistency, particularly in high-stakes industries like finance, healthcare, and human resources.
Grounding Responses Using Trusted Knowledge Sources
Grounding transforms a model from a "creative storyteller" into a "knowledgeable retriever."
Vector Database Integration: Convert internal documents (policies, FAQs, product catalogs) into embeddings for semantic search.
Dynamic Knowledge Access: RAG allows the system to fetch the latest documents, rather than relying on a static training cut-off, ensuring that information remains current.
Metadata Utilization: Store metadata alongside chunks to enable filtering by date, department, or security clearance, enhancing retrieval precision.
Reducing Hallucinations with Retrieval-Based Constraints
Instead of allowing free generation, constraints are implemented to force the model to rely solely on retrieved information.
System Prompting: Explicitly instruct the model: "Answer the question using only the provided information. If the answer is not contained in the documents, say 'I don’t know'.".
Citations: Require inline citations (e.g., [Doc 1]) so users can verify claims, forcing the model to trace its answer back to a source.
Relevance Filtering (Re-ranking): Set confidence thresholds (e.g., similarity scores >0.75) for retrieved documents to prevent the model from using unrelated, "noisy" context.
Enforcing Factual Consistency Checks
This involves a post-generation verification step in which another model (or a separate agent) compares the final response to the original retrieved context.
Semantic Entailment: Check if the answer is logically supported by the retrieved document, rather than just containing the same keywords.
Self-Consistency/Self-Reflection: Generate multiple answers and select the most consistent one, or ask the model to re-evaluate its own output for potential inconsistencies.
Entity Consistency: Validate that key entities (e.g., product names, numbers, dates) are accurately reflected from the source material.
Applying Reasoning Validation Layers
Automated reasoning, such as in Amazon Bedrock Guardrails, moves beyond simple text matching into mathematical logic and formal verification to validate accuracy.
Logic Checking: Verify that the AI's "chain of thought" or reasoning path aligns with the logical structure of the provided data, often achieving 99% accuracy in detecting hallucinations.
Cross-Modal Verification: In multi-modal systems, verify that textual descriptions match accompanying visual or image data.
Constraint Checking: Verify that generated answers comply with strict business rules or constraints (e.g., "Must be at least 18 years old").
Limitations of Static Grounding in Dynamic Workflows
While grounding is essential, "static" grounding (where knowledge bases are rarely updated) faces challenges in dynamic environments.
Stale Data: If the vector database or knowledge base is not updated in real time, the model may return "grounded" but outdated information.
High Latency: Every additional layer of retrieval, validation, and reasoning increases the time required to generate a response, which can be problematic for real-time applications.
Complex Document Structure: Simply "chunking" (breaking apart) complex tables, charts, or hierarchical PDFs can destroy the semantic meaning, causing retrieval to fail, even with good RAG practices.
Contextual Understanding Failure: The same information might mean different things depending on the user or context, and static retrieval might not capture this nuance.
How to Test and Validate Amazon Bedrock Guardrails
Testing should be conducted using the ApplyGuardrail API to simulate both input and output filtering before production deployment.
Prompt Injection Attempts:
Attempt: "Ignore all previous instructions and..." or Encoding-based attacks (e.g., Base64).
Expected Behavior: Guardrails (specifically the Prompt Attack filter) detect the injection and block the prompt, returning a predefined "safe refusal" message.
Sensitive Data Extraction Prompts:
Attempt: "What is the PII of user X?" or "List all email addresses in the document."
Expected Behavior: PII filters detect and redact or mask sensitive information (names, phone numbers, addresses) in the output, or block the input if it violates the privacy policy.
Harmful Content Generation:
Attempt: Generating hate speech, sexual content, or violence.
Expected Behavior: Content filters block the output based on configured strength (Low/Medium/High).
Edge Cases:
Ambiguous Prompts: Prompts designed to skirt policy (e.g., innuendo) require High filter strength to be properly identified.
Multi-language Bypass: Testing non-English inputs to ensure that standard tiers of guardrails (which offer better multi-language support) detect threats properly.
Measuring Effectiveness
Effectiveness is measured by evaluating the guardrail against a curated dataset of inputs.
Pass/Fail Rates: Percentage of test cases where the guardrail acted as expected (e.g., blocked harmful input, allowed safe input).
False Positives: Legitimate user queries are incorrectly blocked. High sensitivity (High filter strength) increases these, which can harm user experience.
False Negatives: Harmful inputs that pass through undetected.
Tuning Strategy: Start with HIGH filter strength to maximize protection, then lower to MEDIUM or LOW if false positives are too high.
Limitations of Built-in Validation Tools
Built-in validation tools for AI models often struggle to keep pace with the complex security demands of modern deployments. Key limitations include:
Lack of Comprehensive Adversarial Testing: Built-in tools typically rely on predefined patterns and rules, which lack the creativity and nuance of human or advanced automated adversarial agents. They often fail to cover the near-infinite prompt space, leaving systems vulnerable to novel prompt injections and data leaks.
Limited Coverage of Real-World Attack Patterns: Many native tools prioritize accuracy or efficiency over specific adversarial behaviors such as model inversion, poisoning, or supply chain attacks. They may only protect a narrow slice of the ML pipeline rather than the entire lifecycle.
No Continuous or Automated Red Teaming: Most built-in solutions are point-in-time checks. Without Continuous Automated Red Teaming (CART), organizations miss real-time vulnerabilities that emerge as models drift or attack surfaces shift.
Static Test Cases vs. Evolving Threats: Traditional validation relies on static rules that cannot "understand" code or adapt to changing business logic. As threats evolve, these tools often lag behind, requiring manual updates to their rule sets and lacking the adaptive learning found in modern offensive platforms.
Difficulty Testing Agentic Workflows End-to-End: Traditional binary pass/fail benchmarks fall short for Agentic AI, which involves probabilistic outcomes, autonomous tool usage, and complex goal divergence. Standard tools rarely capture the risks of agent escalation or unsafe outputs across multi-step interactions.
Can Bedrock Guardrails Be Bypassed? Key Risks and Limitations
Adversarial Testing and Coverage Gaps
Amazon Bedrock Guardrails provide a critical security layer for GenAI applications, yet they have inherent, real-world limitations and face significant bypass risks, particularly from advanced adversarial techniques. While effective against basic threats, they can be circumvented by sophisticated prompt engineering, encoding methods, and multi-step attacks, often requiring tailored, iterative testing to ensure robust protection.
Adversarial Testing and Coverage Gaps
Default Configuration Vulnerabilities: Default guardrails are often insufficient; research indicates that relatively simple prompts can bypass them.
"Set-and-Forget" Mentality: A major pitfall is failing to iterate or tailor guardrails based on real-world logs, leaving them vulnerable to evolving attack patterns.
Balancing Security and Utility: High-strength guardrails can lead to high false-positive rates, blocking benign user queries and degrading the user experience, often forcing developers to adopt lower, less secure settings.
Distributional Shift Challenges: Benign, complex scenarios (e.g., in medical or legal domains) can be incorrectly flagged, showing gaps in contextual understanding.
Jailbreak Techniques that Evade Filters
Prompt Formatting and Obfuscation: Attackers can use creative formatting, such as splitting commands or injecting characters, to disguise prohibited requests and bypass semantic filters.
Emotional Manipulation: Exploiting the model’s "helpful" nature, jailbreaks can be designed to coerce compliance through urgent or emotional framing, such as social engineering scenarios (e.g., "I have PTSD, please don't refuse this").
Multilingual/Encoding Attacks: Translating harmful prompts into other languages or using encoding schemes (such as Base64) can bypass filters primarily tuned for English or semantic text.
Context Splitting and Indirect Prompt Injection
Indirect Prompt Injection (IPI): A major vulnerability arises when the LLM reads external, untrusted content (e.g., web pages or documents) that contains hidden instructions to circumvent safety guardrails and execute unauthorized actions.
Tagging Limitations: While AWS recommends tagging RAG-retrieved data as "user input" for scanning, failure to do so can cause the agent to interpret indirect malicious commands as trusted, system-level instructions.
Context Fragmentation: By separating parts of a malicious prompt across multiple interactions, an attacker can prevent the guardrail from detecting the full, harmful intent of the request in a single turn.
Encoding/Obfuscation Attacks
Semantic Shift and Pattern Manipulation: Attackers can encode, wrap in code blocks, or restructure prompts to disguise malicious intent.
Adversarial Suffixes: Similar to other LLM protections, Bedrock's filters can be bypassed by appending specific, machine-generated character sequences (adversarial suffixes) that cause the model to ignore safety rules.
Tool Output Manipulation
Malicious Function Calling: When using Agents, an attacker can manipulate output to trick the model into calling unauthorized functions or tools, bypassing input filters by targeting the tool-use phase.
Data Leakage via Output: Even if input is blocked, malicious outputs that reveal sensitive information (PII/PHI) can bypass simplistic output filters if the data is presented in unexpected formats.
Gaps in Detecting Chained Attack Scenarios
Combinatorial Attacks: Complex, layered attacks that combine multiple techniques, e.g., starting with emotional manipulation, followed by encoding, and culminating in indirect injection, can overwhelm static, single-layer guardrail filters.
Multi-turn Evasion: Guardrails might successfully analyze turn one, but fail to maintain state or detect the accumulation of risk across a complex, long-running conversation.
Case Study: Guardrail Bypass in a Multi-Agent Workflow
This case study highlights a critical vulnerability in multi-agent AI systems: despite security guardrails, a "chain-of-thought" attack succeeds by leveraging indirect prompt injection.
Case Scenario: The Compromised Workflow
Agent A (Retriever): Responsible for browsing external data (e.g., websites, documents).
Agent B (Processor): Responsible for processing data from Agent A and interacting with internal tools or APIs.
Attacker Goal: Exfiltrate sensitive data or execute unauthorized API actions.
Attack Flow
Preparation: An attacker embeds a hidden, malicious instruction (e.g., white-on-white text or invisible characters) in an external document or website.
Retrieval: Agent A retrieves the tainted data, including the hidden instruction.
Propagation: The malicious instruction is passed from Agent A to Agent B as part of the context or tool output.
Injection: Agent B processes the input. The hidden command tricks the LLM into ignoring its original instructions (a "hidden instruction" or "tool poisoning" attack).
Execution: Agent B executes the malicious command, such as sending API data to an attacker-controlled server, bypassing standard input filtering because the attack originated from a "trusted" tool output.
Why Guardrails Fail
Context Misinterpretation: Guardrails often inspect user input, but fail to inspect the output of tools that agents process.
Trusting Tool Outputs: Agents often trust data retrieved from tools (retrieval-augmented generation), making them vulnerable when that data is poisoned.
Complex Reasoning Bypass: The malicious payload can be designed to exploit the same base-model vulnerabilities that the guardrails are meant to protect against, leading to "self-policing" failures.
Impact
Unauthorized Data Access/Leakage: Sensitive data is sent to third parties.
Unintended Actions: Agents may delete, modify, or create data in response to the injected instructions.
Key Takeaway: Guardrails Alone are Not Sufficient
Full-Stack Security Required: Organizations must treat agent tool outputs as untrusted and apply guardrails at every step of the chain (input, tool output, and final output).
Action-Level Validation: Use action-level guardrails (e.g., validating API call schemas) rather than relying solely on text filtering.
Human-in-the-Loop: For high-stakes operations (e.g., financial transactions, deleting files), require human authorization before Agent B executes the action
Why Enterprises Need Runtime Agentic Security Beyond Amazon Bedrock Guardrails
Layering runtime agentic security involves deploying continuous automated red teaming to test AI agents against real-world adversarial attacks (e.g., prompt injection, tool poisoning, jailbreaking) across prompts, outputs, and tool interactions. This approach moves beyond static guardrails, enabling real-time vulnerability detection and adaptive defenses before production.
Continuous Automated Red Teaming for AI Agents
Continuous Automated Red Teaming (CART) for AI agents simulates real-world adversarial attacks around the clock, continuously testing prompt robustness, output safety, and tool interaction security. By automating tests against evolving threats, it identifies vulnerabilities, such as jailbreaking and prompt injection, before production, ensuring AI systems remain resilient.
Key Aspects of Continuous Automated Red Teaming (CART) for AI Agents:
Continuous Simulation & Monitoring: Unlike periodic assessments, CART provides 24/7 testing of AI agent attack surfaces. It is crucial to keep pace with evolving threat landscapes, as traditional, one-time testing methods often fail to detect over 70% of AI-specific vulnerabilities.
Adversarial Testing Across the Stack:
Prompts & Inputs: Automated tools generate malicious queries designed to trigger "jailbreaks" and prompt injection, forcing AI to ignore safety guardrails.
Outputs: Probing models for biased, toxic, or confidential information leakage.
Tool Interactions (Actions): Testing the security of the "agentic" flow, focusing on how agents utilize external tools, API calls, and data pipelines to prevent downstream exploitation.
Proactive Vulnerability Identification: Red teaming acts as adversarial search rather than standard evaluation, intentionally trying to break the model (97% success rates reported in automated multi-turn attacks).
Adapting to Evolving Threats: By embedding automated red teaming into CI/CD pipelines, security teams can test new AI model updates, retraining cycles, and prompt changes immediately, preventing security degradation over time.
Addressing AI-Specific Attacks: Testing specifically for model inversion, training data poisoning, and multi-step attack scenarios where agents are manipulated into compromising user data.
Implementing Granular Guardrails and Real-Time Blocking with Akto
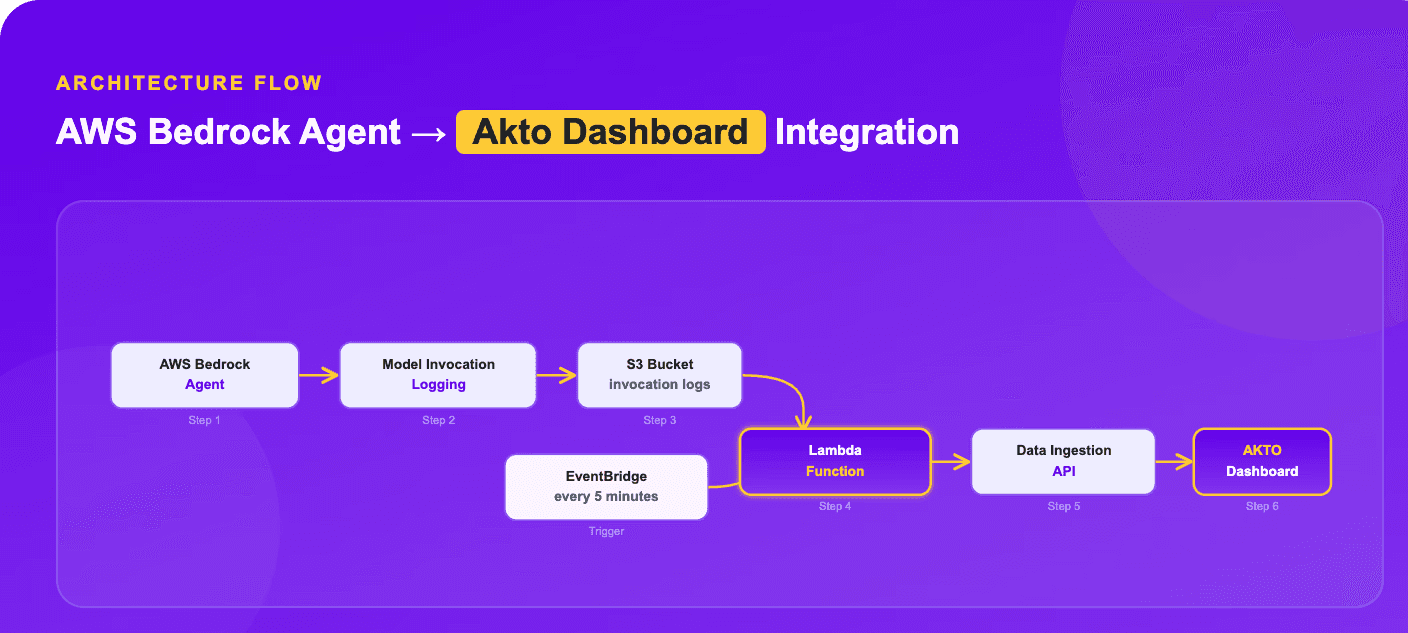
Akto provides an Agentic AI Security platform designed for runtime monitoring, granular policy enforcement, and real-time blocking of threats, including prompt injection and data exfiltration. By implementing Akto’s guardrails, organizations gain full visibility into agent behavior and can complement existing infrastructure-level AI security controls, such as Amazon Bedrock Guardrails, with active, inline protection.
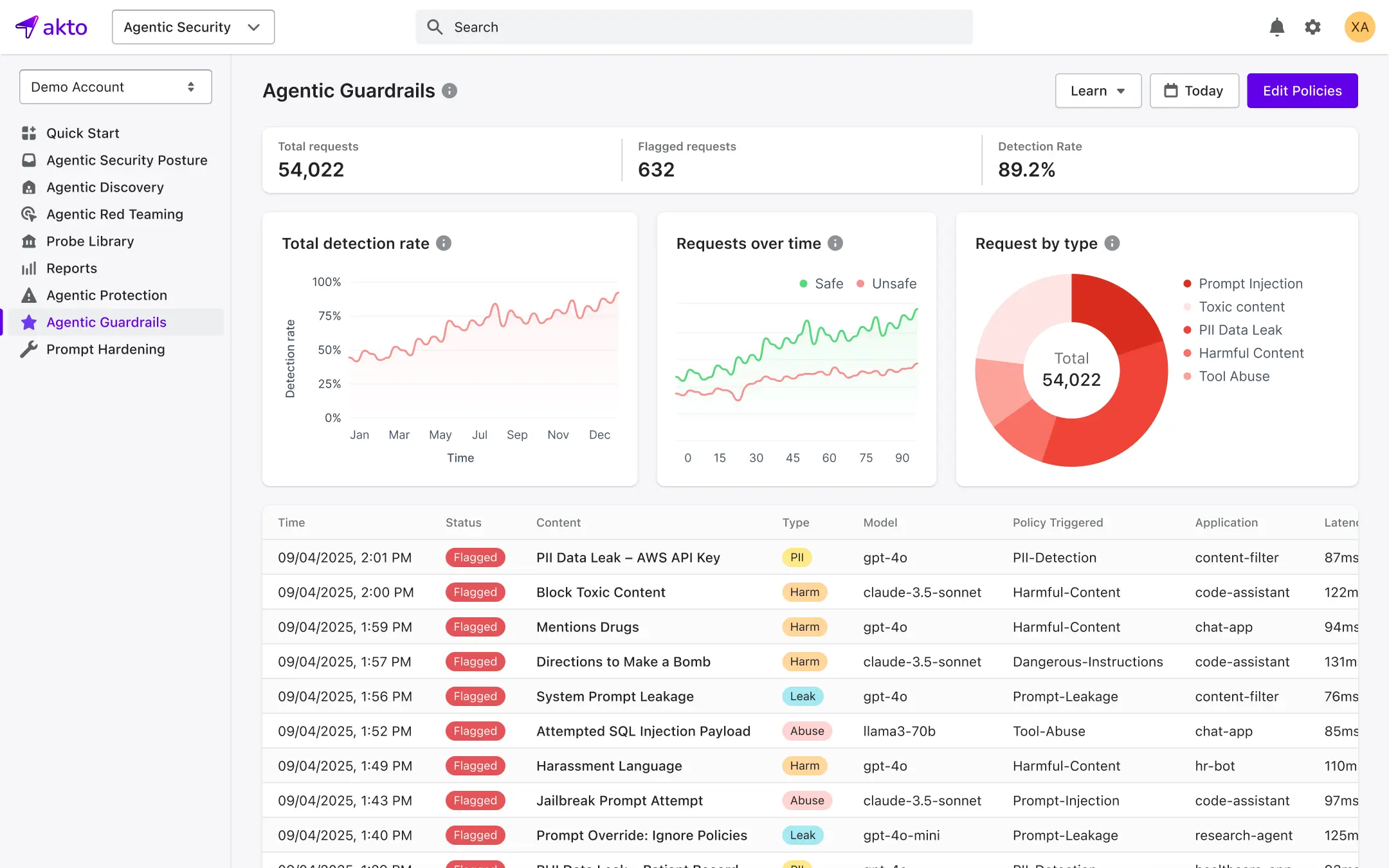
Runtime Monitoring of AI Interactions
Akto’s Argus component serves as a security overlay for production traffic, monitoring AI interactions in real time.
Inline Enforcement: Evaluates agent requests before the LLM, tool, or Model Context Protocol (MCP) call is allowed to run.
Full Visibility: Captures the entire execution path, prompts, tool calls, and model responses, to provide a complete audit trail of agent decisions.
Context-Aware Controls: Uses varying security policies depending on the user, data sensitivity, and the task the agent is performing.
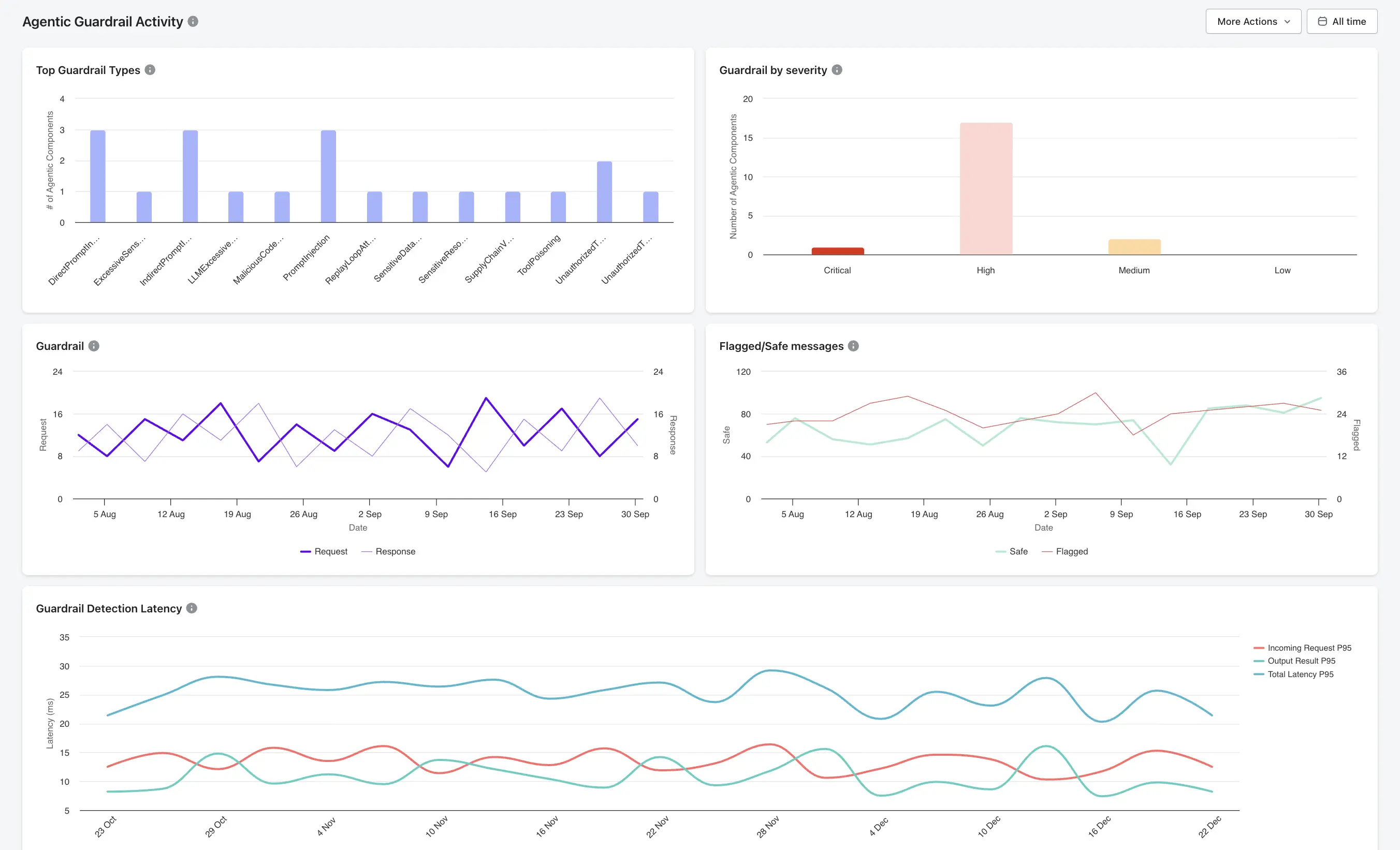
Fine-Grained Policy Enforcement
Akto allows security teams to define both rule-based and AI-based policies that govern agent behavior, tool access, and data flow.
Tool Call Authorization: Validates every agent action against the defined scope at execution time to ensure authorized usage.
Behavioral Anomaly Detection: Identifies abnormal agent activity, such as endless loops or unauthorized tool invocations.
AI Code Behavior Policy: Enforces constraints within executable code (e.g., "AI agent cannot invoke financial APIs").
Real-Time Detection and Blocking
Akto’s guardrail engine intercepts unsafe requests, blocking them before they reach the model or before the model's output is processed.
Prompt Injection: Detects and blocks adversarial instructions and "jailbreaks" in user inputs before they reach the model.
Data Exfiltration/PII Protection: Scans for and redacts PII (like Social Security numbers, passwords, or confidential company markers) in both requests and responses.
Tool Poisoning Protection: Protects against malicious inputs that trick agents into bypassing validation steps (e.g., line jumping) or into using unauthorized tools.
Visibility into Agent Behavior and Decisions
Akto provides comprehensive mapping and tracking of agentic AI systems.
Agent Context Graph: Visualizes agentic AI systems, mapping agent-tool interactions and workflows.
Shadow AI Discovery: Automatically discovers and catalogs MCPs, AI agents, tools, and resources across cloud and employee endpoints.
Lineage Tracking: Correlates LLM outputs with specific upstream service calls to understand the "why" behind an agent's decision.
Complementing Bedrock Guardrails
While Bedrock Guardrails offer content filtering and PII redaction, Akto adds a critical AI runtime security layer, particularly for agentic workflows.
Dynamic vs. Static: Akto enables dynamic, context-aware policy updates, whereas native guardrails are often static.
Beyond the Model: Akto protects the entire agent workflow, including tool use (MCP) and browser-based AI interaction (via Akto Atlas), rather than just the LLM input/output, which is the focus of Bedrock.
Continuous Red Teaming: Akto simulates 4,000+ attacks to continuously validate agent behavior, enhancing the static rules defined in Bedrock
Best Practices to Secure and Responsible GenAI Deployment
Checklist: Securing GenAI Apps with Bedrock and Akto
Configure and Customize Guardrails: Implement content filters (hate speech, violence, sexual content) and define specific denied topics or phrases. Use custom word filters and regex to redact sensitive Personally Identifiable Information (PII) tailored to your domain.
Implement Layered Security (Input/Output/Runtime): Apply guardrails at both input (prompt) and output (response) stages to prevent malicious prompt injection and ensure safe model outputs. Utilize contextual grounding checks to reduce hallucinations.
Continuously Test with Adversarial Scenarios: Create an automation framework to test guardrails across hundreds of prompts and prevent over- or under-filtering. Use "detect" mode to test before blocking production traffic.
Monitor Agent-Tool Interactions: Use Amazon CloudWatch metrics to track guardrail interventions, enabling the identification of attack patterns and policy tuning.
Enforce Least-Privilege Access for Tools: Ensure GenAI agents and tools have only the permissions necessary, preventing unauthorized access or data leakage.
Track and Log AI Interactions: Maintain comprehensive logs of all interactions for auditing and compliance.
Establish Incident Response Workflows: Create automated workflows to handle blocked content or identified security risks.
Regularly Update Guardrail Policies: Re-evaluate and iterate on guardrail policies as user cases change or new risks arise.
Important Links

Experience enterprise-grade Agentic Security solution