

Researchers found a critical security vulnerability in Ollama that allows unauthenticated attackers to leak the entire Ollama process memory, potentially impacting 300,000 servers globally.
CVE-2026-7482, dubbed "Bleeding LLama," is a critical unauthenticated heap out-of-bounds read vulnerability (CVSS 9.1) in Ollama's GGUF model loader. It lets an attacker dump the entire process memory of a running Ollama server with just 3 API Calls.
In this blog, we dive deep into the vulnerability, break down how the exploit works, and lay out a practical roadmap to secure your Ollama deployments before attackers get there first.
What is Ollama?
Ollama is an open-source platform that lets you run LLMs directly on your own machine instead of relying on cloud services like ChatGPT, Claude, etc.
It enables you to download, host, and interact with models like Llama, Mistral, and others locally on your machines.
With nearly 170K GitHub stars, more than 100 million Docker Hub downloads, Ollama has emerged as the de facto standard for running open-source models locally.
What is Bleeding Llama and What does it Expose?
Ollama's GGUF parser (in all versions prior to v0.17.1) blindly trusted tensor metadata declared inside uploaded model files. An attacker who inflates those values forces the server to read past its allocated buffer, leaking everything in heap memory.
GGUF (GPT-Generated Unified Format) is the standard file format for packaging LLM weights, metadata, and tokenizer information for local inference. Every time a user creates a custom model from an uploaded file, Ollama parses this format and processes its tensors through a quantization pipeline.
Quantization reduces the precision of numbers stored in a model's tensors, making the model smaller and faster to run. In GGUF files, F32 stores each number in 4 bytes while F16 uses only 2. Converting F32 down to F16 results in loss of some data - decimal precision is permanently lost.
But converting F16 to F32 is completely lossless. The attacker deliberately triggers the lossless F16→F32 path so that leaked heap data survives the conversion intact and readable.
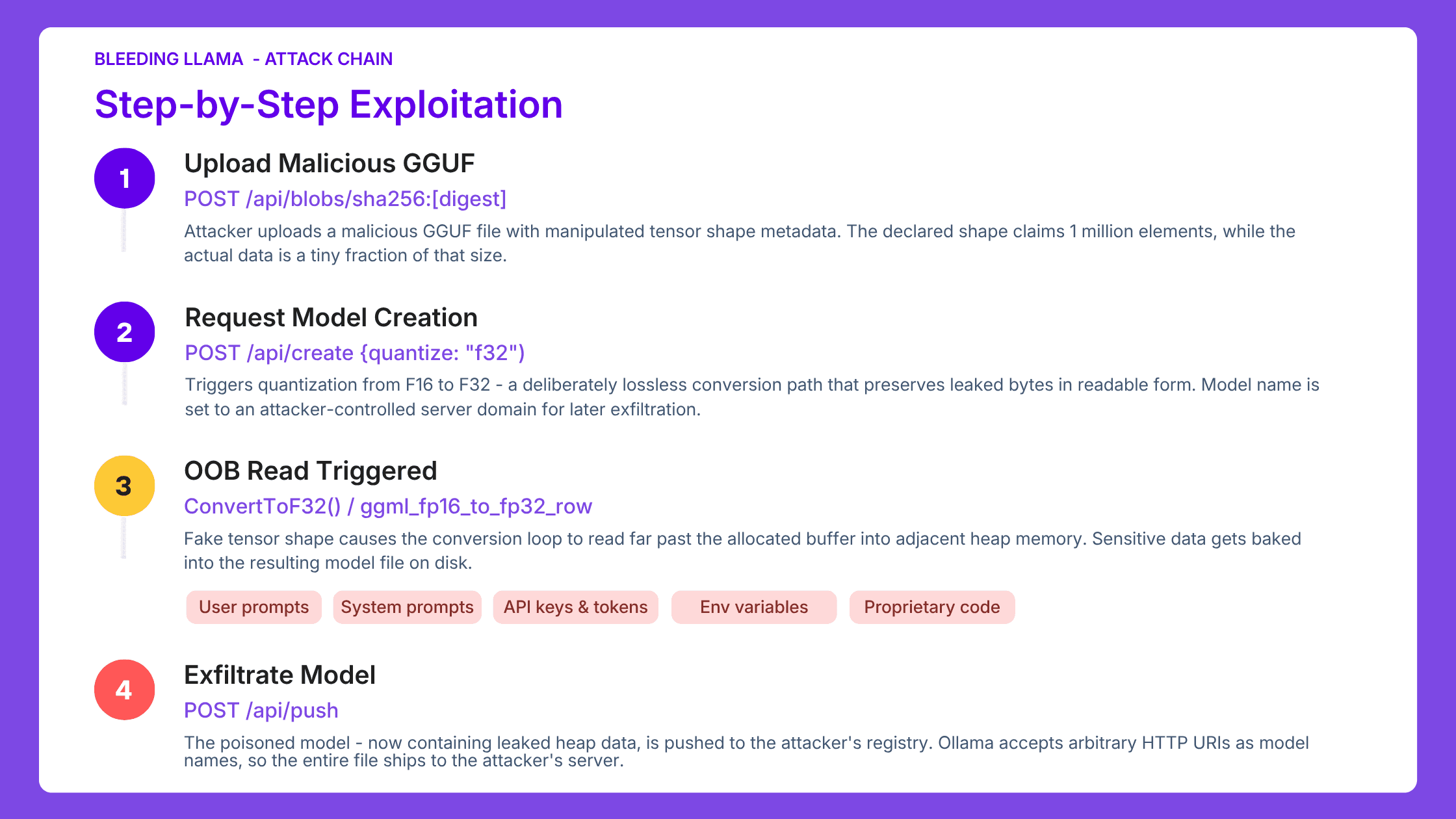
The WriteTo() function in server/quantization.go uses Go's unsafe package, bypassing the language's built-in memory safety guarantees. Without validation, the inflated tensor shape causes the conversion loop to read far past the allocated buffer into adjacent heap memory - pulling in user prompts, system prompts, environment variables, API keys, and tool outputs from connected services.
The attacker then exploits a second design gap. Ollama's /api/push endpoint accepts arbitrary HTTP URIs as model names with no validation. The poisoned model file, now containing leaked heap data, ships directly to the attacker's server.
As security researcher Dor Attias put it: "An attacker can learn basically anything about the organization from your AI inference. API keys, proprietary code, customer contracts, and much more."
The risk compounds when engineers connect Ollama to coding tools. Every tool output flows through the Ollama server, lands in heap memory, and becomes part of what an attacker steals.
Course of Action: Mitigation and Recommendations
1. Upgrade immediately to Ollama version 0.17.1, which patches CVE-2026-7482. Verify with ollama --version. If you are running Docker, pull the latest image.
2. Restrict network access. Firewall Ollama's API port (default: 11434) to localhost or trusted internal CIDRs only. Ollama should never be reachable from the public internet. On local networks, isolate Ollama instances on secure network segments behind firewalls.
3. Deploy an authentication proxy (e.g., OAuth2 Proxy, nginx with mTLS, Cloudflare Access, or Tailscale) in front of any network-accessible Ollama instance. The REST API has no built-in auth. Treat any unauthenticated Ollama endpoint as an open data leak.
4. Rotate all secrets. Assume any API keys, tokens, credentials, or environment variables handled by an exposed Ollama instance are compromised. This includes OpenAI/Anthropic tokens, database connection strings, and cloud service keys passed as environment variables to the Ollama process.
5. Audit GGUF ingestion pipelines. Validate model file sources and apply integrity checks before loading third-party GGUF files. The attack vector depends on the ability to upload a crafted GGUF, so controlling what files reach the server is a direct mitigation.
6. Monitor for anomalous model push activity. Alert on /api/create and /api/push calls with unusual model names, especially those containing HTTP URIs pointing to unknown registries. This is the exfiltration path.
Why Akto Atlas Exists for Exactly This Scenario
Atlas is built for employee AI usage governance, shadow AI discovery, and endpoint visibility. The Bleeding LLama scenario maps to every pillar:
Discover if employees are running Ollama or other local inference servers.
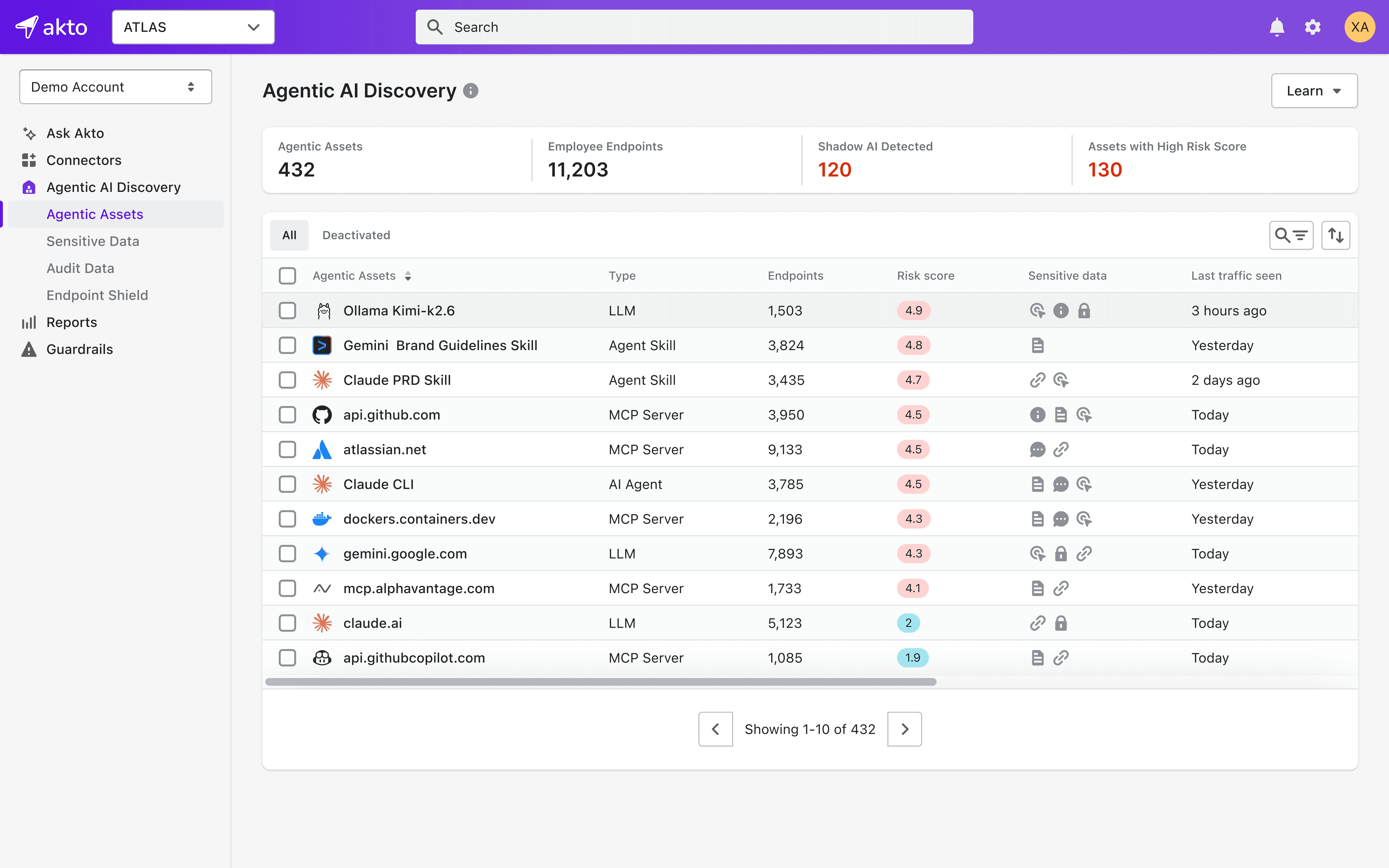
Akto Atlas surfaces every AI tool running across your organization: browser-based GenAI services, IDE-integrated agents, local inference servers like Ollama, and MCP servers. It does not matter whether they went through procurement. A developer who spins up Ollama without filing a ticket still shows up in Atlas the moment traffic is observed. Security teams get a continuous, auto-updating inventory of all LLMs, MCP servers, skills, AI Agents installed on employee endpoints.
Identify which users and devices have exposed Ollama instances.
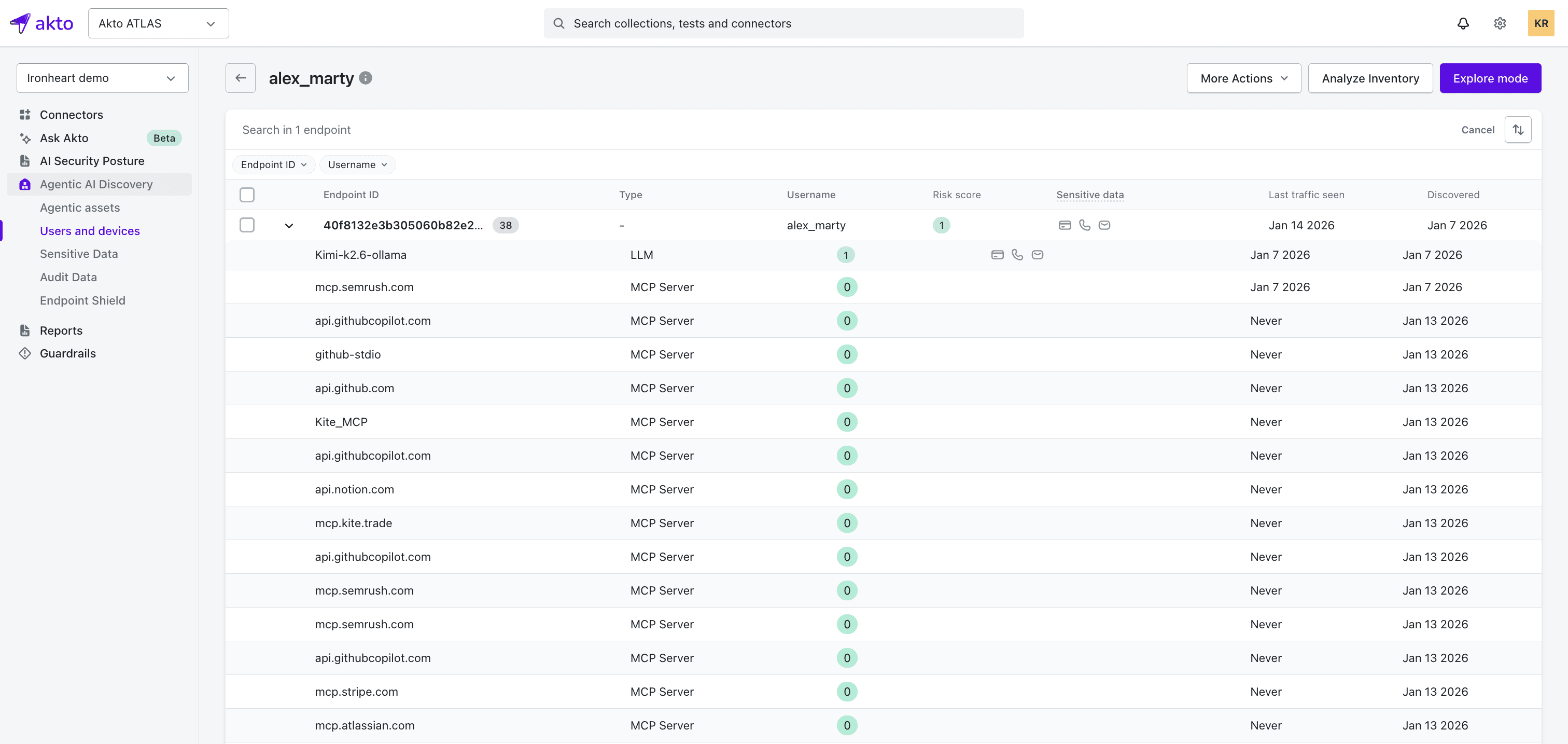
Akto Atlas flags an unauthenticated Ollama instance and ties that instance to the specific employee or device where it is installed. Security teams can filter by risk level, see what sensitive data has flowed through the instance, and drill into that user's AI interactions. That turns a vague alert ("there's an exposed Ollama somewhere") into an actionable investigation - this backend engineer on this laptop has been running an unpatched instance for three weeks, and credentials have passed through it.
Stop sensitive data from leaking through Ollama before it hits heap memory.
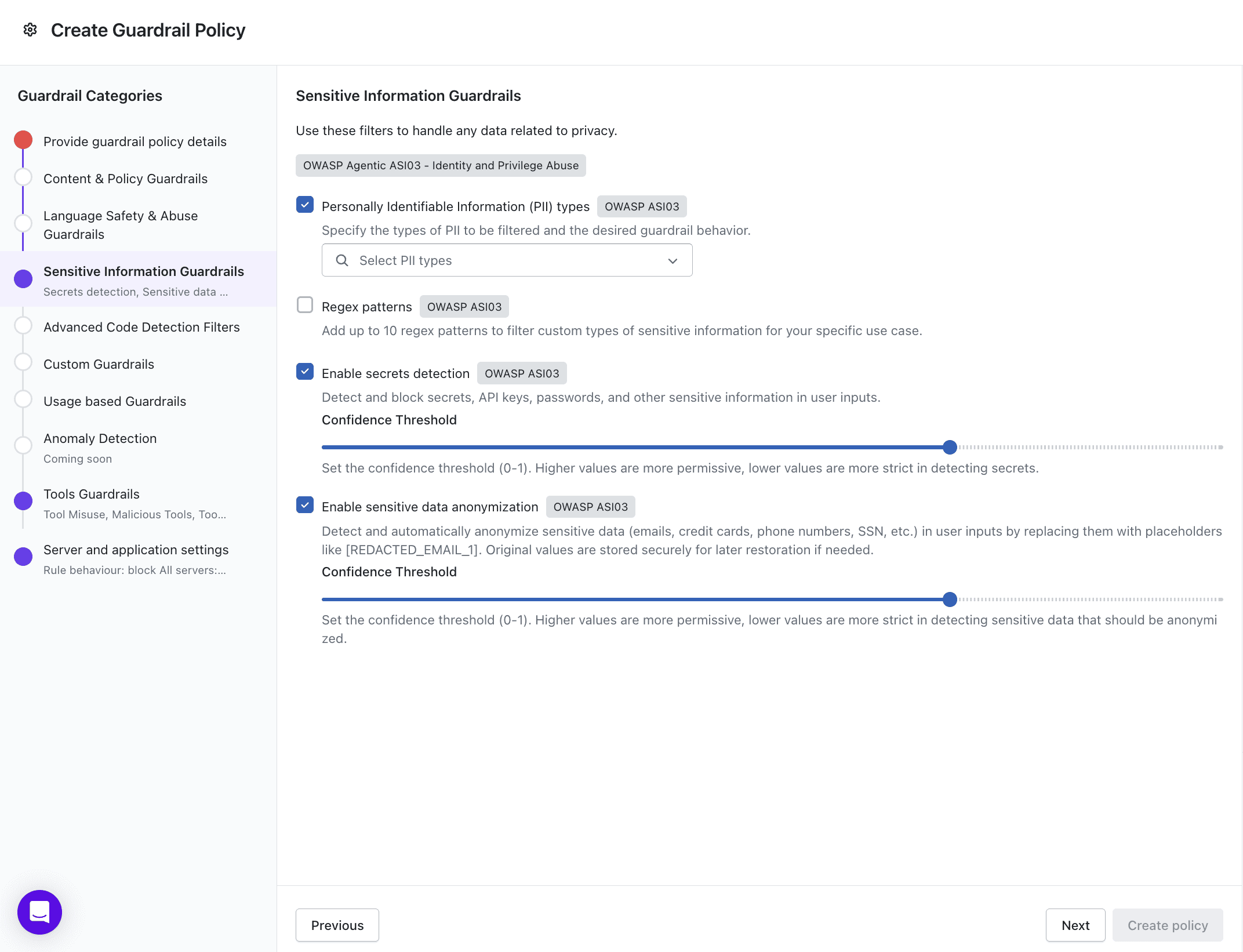
Atlas Guardrails run directly on employee devices, inspecting every prompt, response, and tool call before it leaves the machine. They block sensitive data (PII, secrets, source code) from reaching AI tools, detect prompt injection and jailbreak patterns, and enforce policies on shadow AI tools outside the approved list. Every decision is logged to the Akto dashboard with full user and device context. Even if a vulnerability like Bleeding Llama exists in the infrastructure, AI Guardrails reduces the blast radius by keeping sensitive data out of the AI pipeline in the first place.
The lesson from CVE-2026-7482 is not just "patch your Ollama." It is that every organization running local AI inference needs visibility into what is deployed, where it is exposed, and what data passes through it, before the next vulnerability drops.

Experience enterprise-grade Agentic Security solution