Claude Code Security: Risks, Limitations, and Best Practices for Agentic AI
Explore Claude Code security: permission model, built-in protections, key limitations, and best practices to secure agentic AI workflows in production.

Sucharitha

Claude Code doesn't just answer one-off questions - it can write files, execute shell commands, call APIs, and make decisions across multi-step workflows with minimal human input. That's exactly what makes Claude Code security a growing concern for engineering and AppSec teams. When an AI agent can read your codebase, modify configuration, and trigger CI/CD pipelines, a single compromised prompt or over-permissioned session can lead to data exposure, unauthorized deploys, or a compromised production environment.
In this blog, we break down how Claude Code's security model works, where its built-in protections fall short, and the best tactics to secure its usage in production.
Understanding Claude Code Security: Architecture and Core Mechanisms
Before you can assess risk, you need to understand what Claude Code is actually doing at the architecture level.
Claude Code is not a plugin or an add-on feature. It’s a terminal-based agentic AI system that operates with direct access to your local environment. It reads files, runs bash commands, and interacts with external services, capable of deciding its next steps based on context and instructions.

Permission Model and User Control
Claude Code's permission system is the first layer of agentic AI security and is the first step to understanding its internal mechanism.
By default, Claude Code operates in an interactive mode where it requests explicit approval before taking actions, such as writing files, executing commands, and making network calls. The model can then produce outputs and wait for a developer to confirm.
However, Claude Code also supports a “dangerously-skip-permissions” flag that is capable of bypassing the confirmation loop and allows the agent to execute actions with human sign-off.
What security teams need to do:
Treat “dangerously-skip-permissions” like a root login and document every use case, restrict it to sensitive environments, and run audit trails
Define explicit tool allowlists before deploying Claude Code into any automated pipeline
Separate Claude Code's operating environment from anything with write access to the production infrastructure
Built-in Protections: Prompt Injection and Privacy
Claude Code ships with two categories of built-in AI guardrails, i.e., prompt injection resistance and sensitive data protection.
Regarding prompt injection attacks, Claude Code is trained to treat instructions that arrive via environmental context, such as files, tool outputs, or external content, with suspicion. If a malicious file contains hidden, dangerous instructions, the model is designed to flag and refuse.
On privacy, Claude Code avoids hardcoding credentials, flags exposed secrets in code, and monitors for unexpected network calls. There's also network request monitoring built into the system to surface unexpected external calls.
What Is Anthropic's Claude Code Security Feature?
On February 20, 2026, Anthropic launched Claude Code Security, a research-preview product powered by Opus 4.6, now rolling out to Team and Enterprise customers. It's a step beyond the /security-review command Anthropic shipped in August 2025./security-review matches code against known vulnerability patterns, SQL injection, XSS, common auth flaws, the way traditional SAST tools do. Claude Code Security reasons instead: it traces how data moves through an application and how components interact, rather than checking for known-bad signatures.
That reasoning found real bugs pattern matching missed. Anthropic's team validated over 500 high-severity vulnerabilities across production open-source codebases, including logic-level flaws that survived years of expert review. Each finding runs through a multi-stage check, where Claude adversarially re-examines its own conclusion before surfacing a confidence rating to a human reviewer.
That's a genuine leap in vulnerability discovery. But it's also where most coverage stops.
Reasoning Is Not Enforcement
Claude Code Security is a static reasoning layer: It reads code and reasons about what could go wrong. It doesn't run your application, and it has no visibility into what an agent actually does once deployed: which tools it calls, what data it touches, how it behaves under a live prompt injection.
That's exactly where agentic AI security lives. A function can pass static review clean and still be manipulated at runtime into calling the wrong tool or leaking data through a path nothing flagged as risky. Discovery and enforcement are different problems — solving one doesn't solve the other. That's the layer this guide covers next.
Security Capabilities: What Claude Code Security Detects
Most security tools just scan code, look for mistakes, and flag them. However, Claude Code reads code thoroughly, tries to understand what it is supposed to do, and then asks whether it actually does so safely.
Here’s how it's done:
Semantic Vulnerability Detection
Traditional AI security testing tools work by matching code patterns to known bad patterns. Claude Code works differently. It understands what code is trying to do and evaluates whether that intent creates risk.
Claude Code catches like a complete LLM code analysis engine:
Business logic flaws where the code is syntactically correct but functionally insecure.
Authentication gaps, especially while tracking multi-step execution flows
Hard-to-catch insecure data handling
Claude Code's detection quality varies with context window size, codebase complexity, and how clearly the task is scoped.
Diff-Aware and Contextual Scanning
Most scanners look at code changes in isolation, but Claude Code looks at a diff the way a code reviewer does. It asks what the change actually affects, whether it introduces new assumptions, and whether it creates risk when combined with existing code around it.
That context is what makes a security review useful.
The contextual awareness also extends to configuration files, infrastructure-as-code, and dependency changes, not just application code.
Where Claude Code Security Falls Short: Technical Limitations
Two main areas where Claude Code Security takes a back seat:
Blind Spots in Agentic Workflows
Claude Code is meant for simple setups, where there’s just one agent, one developer, and a straightforward environment.
However, real-time production agentic workflows are much more complex.
Here are some major blind spots:
In multi-agent pipelines where Claude Code receives instructions from other models or automated systems, it loses the ability to reliably assess agentic AI vulnerabilities when an instruction is passed or injected by an attacker
A major shadow AI problem, where developers run Claude Code locally against sensitive environments, and security teams have no visibility into what the agent accessed or executed
Claude Code has no memory across sessions. Each session starts fresh, which means no native audit trail, no cross-session pattern detection, and no way to flag suspicious behavior
False Positives, Missed Context, and User Responsibility
Some of Claude Code’s security limitations:
It reasons about code rather than matching patterns, which makes its output inconsistent without full context
Can flag safe code as risky, or miss a real vulnerability, simply because it only saw part of the codebase
A confident finding and an unreliable guess look identical in the output
The output quality depends heavily on how well the task is scoped and how much relevant context is provided
Best Practices for Secure Claude Code Usage
Having Claude Code in your tech stack offers no guarantee of an efficient security strategy. Let’s discuss two of the best practices to secure your Claude Code use cases:
1. Least-Privilege Access and Sensitive Data Controls
The first question to answer before any deployment is this: what can Claude Code access, and should it be allowed the same?
Define that boundary before the tool is fully functional. Claude Code should operate with the minimum permissions needed for the task. So, if a workflow only requires reading code, Claude should have just read-only access.
Some pointers for Claude AI security best practices are:
Keeping Claude Code out of production environments
Eliminate sensitive data before it enters the context window
Establish clear usage policies for developers
Capture inputs, outputs, and tool calls for better auditability and help AI compliance controls do their job
2. Integrating Claude Code Security into Existing AppSec Tooling
Claude Code brings semantic reasoning and contextual judgment. It works best as one layer in a security pipeline and should never be considered as a replacement for the security platforms already in place.
For AI security posture management across the development lifecycle, a practical integration looks like this:
Run Claude Code at the pull request stage for logic-level and context-aware review
Run security platforms in parallel
Feed Claude Code outputs into your existing ticketing and review workflows
Apply runtime protection for GenAI at the infrastructure level
Treat Claude Code like any other third-party tool in your threat model
Beyond Claude Code Security: The Case for Agentic Runtime Protection
Claude Code's built-in guardrails were designed to handle a limited, developer-facing use case.
So, once you move into production agentic deployments, the threat surface expands beyond what Claude or other similar model-level protection tools can cover.
Runtime Threats: Prompt Injection, Tool Abuse, and Data Exfiltration
In agentic systems, Claude Code calls tools, writes to downstream systems, and makes autonomous decisions. And this is the exact surface attackers target.
Prompt injection at runtime is when an attacker can control actions and output by targeting something the agent reads. It could be a file it accesses, a web page, a database record, or another tool.
Tool abuse has a similar pattern. Claude Code operates with a set of tools it can invoke to read files, run shell commands, or perform network calls. A compromised prompt that redirects tool use, calling the wrong command, reading the wrong file, or making an unexpected network request can cause real damage before any human sees the output.
Data exfiltration is the downstream risk. An agent with access to a sensitive file is a huge exfiltration vector if the system has no runtime monitoring in place.
Automated Red Teaming for LLM-Powered Code Tools
What agentic AI systems need is adversarial testing.
Automated red teaming tools designed for LLM-powered systems generate adversarial inputs at scale, gauge how the agent responds to malicious content, and surface failure modes that appear when certain manipulated inputs are passed.
For Claude Code, effective AI red teaming needs to test every realistic way an attacker could feed it malicious instructions, whether through files it reads, tools it calls, or other agents it works with.
How Akto Argus Extends Claude Code Security for Agentic AI
Claude Code’s built-in guardrails are just model-level. It does not handle the happenings during runtime, across pipelines, or within cloud environments. And that’s what Akto Argus is built for.

Akto Argus offers autonomous runtime guardrails & unified security for cloud-deployed GenAI apps, AI agents, and MCP servers.
Here’s how it helps secure AI agents and LLM code applications:
Agentic Discovery and Posture Management
Argus continuously discovers AI assets, such as AI agents, MCP servers, and GenAI apps, deployed in your cloud environment
It offers a clear, centralized view of what exists, where it’s running, and who owns it, eliminating blind spots and shadow deployments.
Since agents are dynamic in nature and prompts and tools tend to change, Argus continuously evaluates risk as changes happen, ensuring security posture reflects current runtime behavior and not just a point-in-time snapshot.
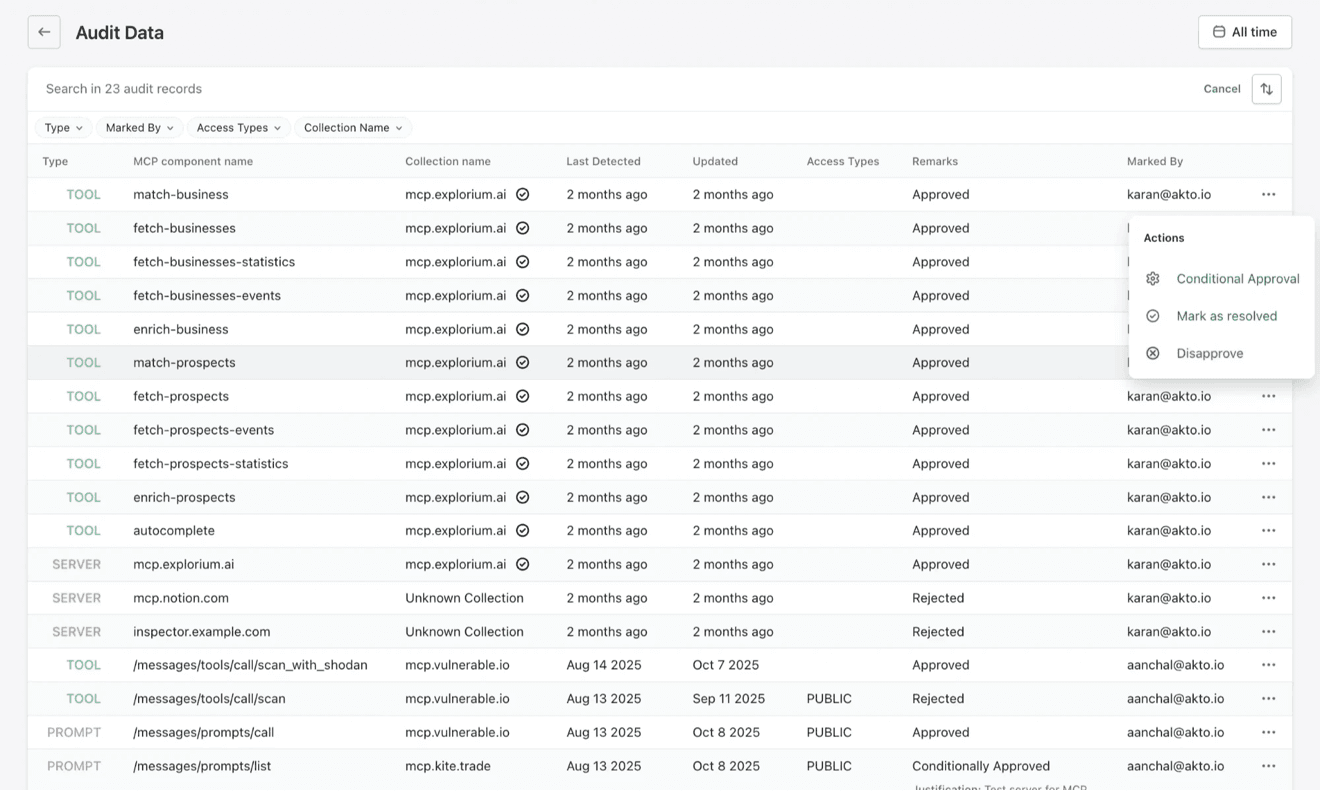
Real-Time Guardrails and Attack Blocking
Actual control must happen at execution and not just at the model level.
Therefore, Akto Argus lets you define runtime guardrails that control agent behavior in production.
It controls real-time behaviour like:
Permission checks, to determine if an agent is allowed a specific action or not
What data can it access
Which tools can it evoke
What categories, topics, or outputs are restricted
These guardrails help block attacks as they are enforced while the agent is operating in production and not after an attack has already happened.
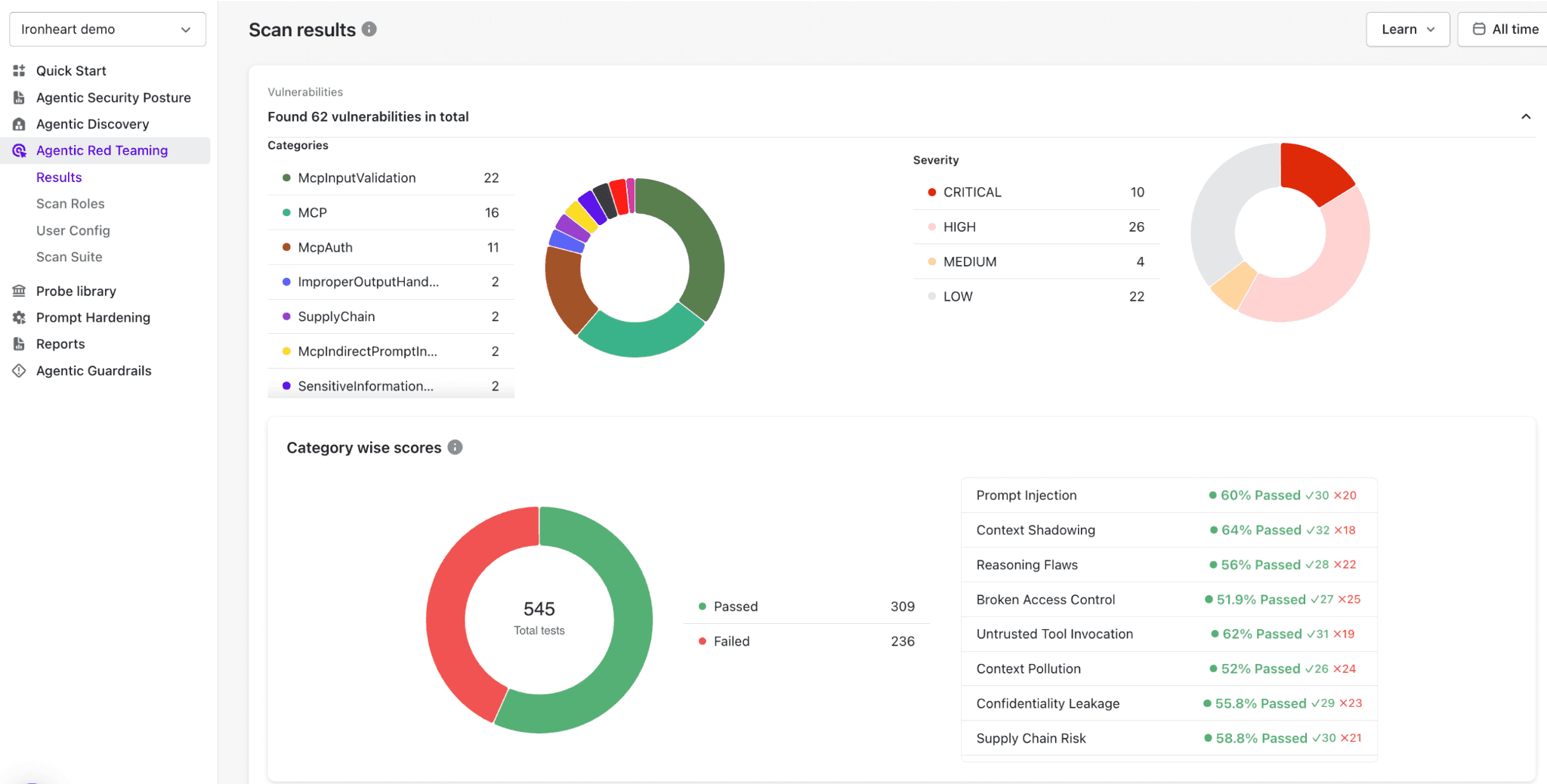
Final Thoughts: Building a Secure Future for AI-Powered Code Tools
Claude Code’s built-in protections are just starting points. Enterprises must never take what happens in production and at runtime for granted.
The answer lies in building continuous monitoring, policy enforcement, and automated security around agentic workflows from the start and not after something goes wrong.
Prompt injection, tool abuse, shadow deployments, and data exposure are no longer theoretical risks and are already happening in organizations at scale.
If your team is deploying Claude Code or an AI agent or an MCP server in production, Akto Argus gives you the visibility, red teaming, and runtime protection to do it safely.
FAQs for Claude Code Security
What is Claude Code Security, and how does it protect AI-powered code tools?
Answer: Claude Code Security refers to safeguards built around AI coding assistants to prevent misuse, data leakage, and unsafe code execution. It protects tools by enforcing boundaries, monitoring behavior, and restricting risky actions.
How does the permission model in Claude Code Security work?
Answer: It uses a permission-based system where access to files, commands, or environments is explicitly controlled. Users or systems grant scoped permissions, ensuring the AI only performs allowed actions.
What types of threats and vulnerabilities can Claude Code detect?
Answer:It can identify insecure code patterns, secrets exposure, prompt injection attempts, and unsafe command execution. It also helps flag dependency risks and suspicious behaviors.
Where are the technical limitations and blind spots of Claude Code Security?
Answer: It may miss novel attack patterns, subtle logic flaws, or context-specific vulnerabilities. Over-reliance on predefined rules can also limit detection of complex, real-world threats.
How can teams secure workflows and sensitive data when using Claude Code?
Answer: Teams should enforce least-privilege access, isolate environments, and avoid exposing sensitive data in prompts. Regular audits, monitoring, and human review add critical layers of security.
Important Links

Experience enterprise-grade Agentic Security solution