GenAI Security Risks: Top Threats, Examples & Mitigation Strategies (2026 Guide)
Explore top GenAI security risks, real examples, and best practices to protect your enterprise in 2026.

Dhruvi

Generative AI is no longer a layer on top of your system. It is part of the system. It reads internal data, reasons over context, calls tools, and increasingly, takes actions. In many environments, it sits directly in the path between user intent and system execution. That changes the nature of security it requires.
Traditional systems are built on predictability. You define logic, validate inputs, and control outputs. If something breaks, it usually breaks in a visible way.
GenAI systems behave differently. They are probabilistic, context-driven, and compositional. The same input can lead to different outputs. Valid inputs can still produce unsafe behavior. And most importantly, they operate across multiple layers at once.
This is the biggest difference between them.
The risk is not in one place. It emerges from how these systems interpret, combine, and act on information across the stack.
In this guide, we are going to understand how GenAI security risks actually show up in production, why they are hard to control, and how to approach them in a way that holds up at scale.
Let’s begin
What are GenAI Security Risks?
To understand GenAI risk, you have to start thinking in terms of interactions a system undergoes.
A typical system looks simple on paper:
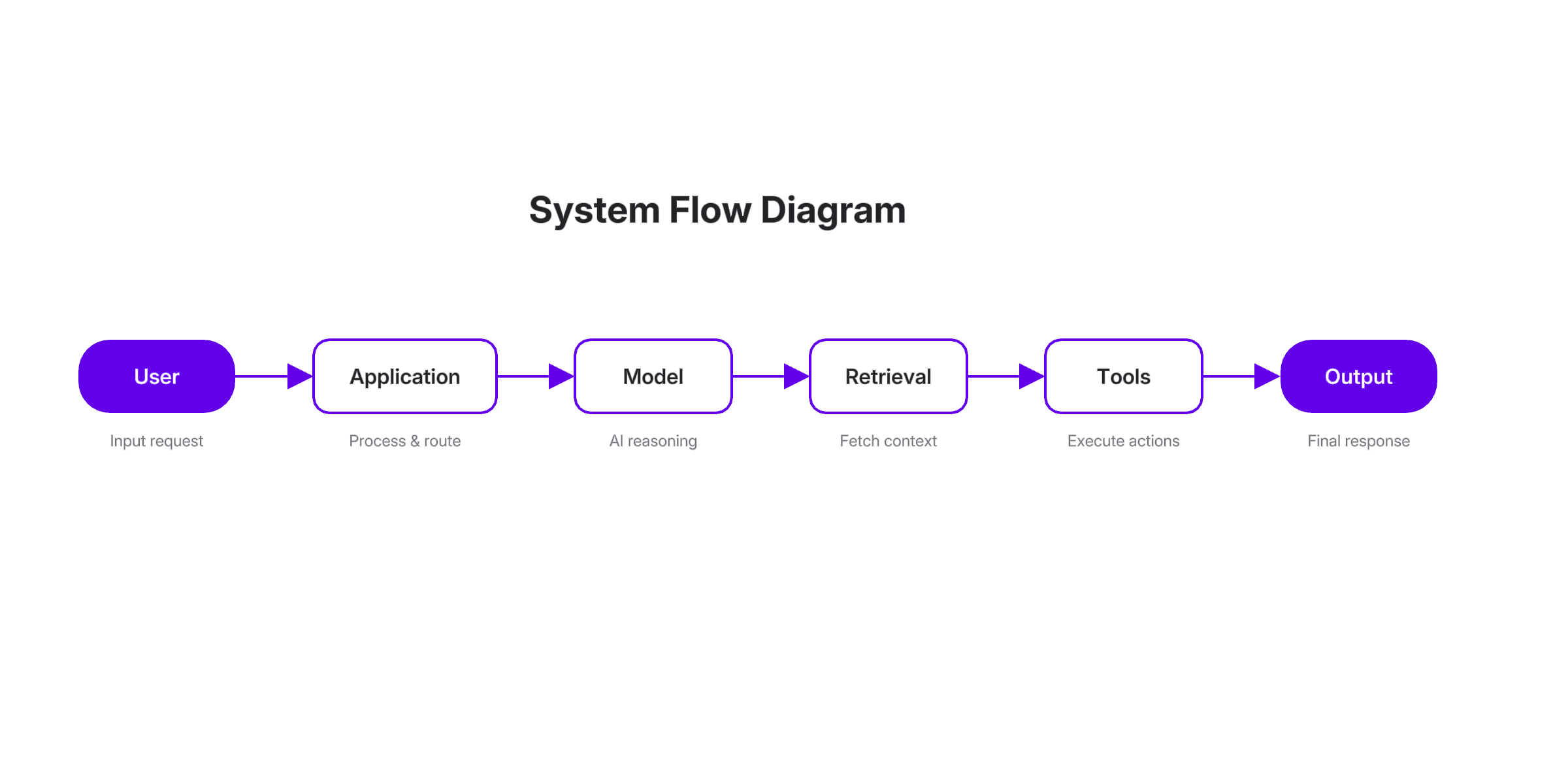
In reality, this is not a linear flow. Context moves across every layer. Instructions, data, and outputs are constantly being combined, reinterpreted, and reused.
That creates a different kind of exposure.
In traditional systems, logic is explicit. You can point to where a decision is made. In GenAI systems, behavior is implicit. It emerges from the interaction between input, context, and model behavior.
This is what defines generative AI security risks vulnerabilities.
First, these systems are autonomous. Even when they are not fully agentic, they influence decisions and trigger downstream actions. As soon as you connect them to tools or workflows, they move from being advisory to operational.
Second, they are deeply tied to data. Not just training data, but runtime data. Prompts, retrieved context, tool outputs, and system instructions all feed into the same decision-making process. If any part of that data flow is exposed or manipulated, the system’s behavior changes.
Third, they operate at scale. A single model often supports multiple workflows. A weakness in one interaction path can affect everything that depends on it.
Why GenAI Security is a Growing Concern
The problem arises with how it is being adopted.
AI is given access to internal knowledge bases because it needs context. It is connected to LLMs because it needs to be useful. It is extended into agents because automation is the next step.
Each of these decisions makes sense in isolation. Together, they create a system where:
The model has visibility into sensitive data
The model can influence or trigger actions
The boundaries between components are blurred
At that point, the system is no longer deterministic. It becomes a dynamic system where behavior depends on context.
This is why traditional security approaches fall short. They assume clear boundaries and predictable behavior. And GenAI systems have neither.
There is also a widening gap between adoption and governance. Many organizations are deploying AI across critical workflows without a clear understanding of how those systems behave under stress or manipulation.
That gap is where Gen AI security risks enterprise environments face are accelerating.
Top 10 GenAI Security Risks (OWASP-Based Framework)
Instead of treating these as isolated issues, it is more useful to see them as different ways the same underlying problem manifests, that is, loss of control over how the system interprets and acts on context.
Prompt Injection
In traditional systems, user input is data. System logic is separate. And in Generative AI systems, both exist in the same context window.
That means an attacker does not need to exploit a vulnerability in code. They can reshape the system’s behavior using language.
A prompt injection attack works by introducing instructions that compete with or override the system’s intended behavior. The model has no inherent mechanism to enforce instruction hierarchy. It responds based on patterns and context, not authority.
This becomes particularly dangerous when the model is connected to tools. A manipulated instruction can influence not just what the model says, but what it does.
The risk here is subtle. Nothing is technically broken. The system is behaving as designed. It is just being guided in a direction you did not intend.
Data Leakage
One of the most common failure modes in GenAI systems is also one of the hardest to detect.
A user asks a question. The system retrieves relevant context. The model generates a response.
Somewhere in that process, sensitive data is included. There is no breach in the traditional sense. No unauthorized access. The system had permission to access the data. It simply surfaced it in the wrong context.
This usually happens because access control is applied too late in the pipeline. By the time the model sees the data, it is already in scope. The model does not distinguish between “allowed to access” and “appropriate to share.”
This is why data leakage remains one of the most persistent Generative ai security risks in enterprise systems.
Supply Chain Risk
GenAI systems are built on top of multiple external components. Foundation models, open-source libraries, third-party APIs, and data sources all become part of the system.
Each of these components introduces trust.
The problem is that this trust is rarely validated.
If a tool returns manipulated data, the model will incorporate it into its response. If a dataset contains biased or poisoned information, the model’s behavior will reflect it. The system has no built-in mechanism to question the integrity of its inputs.
This turns supply chain risk into a systemic issue. It is not about one compromised component. It is about how trust propagates through the system.
Poisoning
Not all attacks aim to break a system. Some aim to influence it.
Data and model poisoning work by introducing carefully crafted data into training or retrieval pipelines. The goal here is long-term influence.
The system continues to function normally. Outputs look reasonable. But under specific conditions, behavior shifts.
This makes poisoning particularly difficult to detect. There is no clear signal that something is wrong. The system is simply “off” in ways that are easy to miss until it matters.
Output Trust
In many organizations, AI outputs are treated as if they were reliable by default.
They are used to:
Generate code
Inform decisions
Respond to customers
Trigger workflows
The assumption is that if the model produced it, it is probably correct.
This is where risk compounds.
GenAI systems are designed to produce plausible outputs, not guaranteed correct ones. When those outputs are fed into downstream systems without validation, errors become actions. The issue here is that these systems are not equipped enough to look at those as “mistakes”.
Excessive Agency
The shift from assistants to agents introduces a new category of risk.
Once a model can take actions, it becomes part of your execution layer. It can query systems, update records, and trigger workflows.
At that point, the impact of a bad decision is no longer informational. It is operational.
If permissions are too broad, or if constraints are weak, a single manipulated input can lead to unintended system behavior. The critical question here is, what the model is allowed to do acts as a deciding factor.
System Prompt Exposure
System prompts define how a model behaves. They encode instructions, constraints, and guardrails.
If these prompts are exposed, they effectively reveal the internal logic of the system.
This gives attackers a roadmap. They can see how the system is structured and where it might be vulnerable. That makes subsequent attacks more precise and more effective.
Protecting system prompts helps preserve the integrity of the system’s control layer.
RAG and Retrieval Risk
Retrieval-augmented generation extends models by pulling in external data.
This is powerful, but it introduces a critical dependency on the integrity of that data.
If retrieval systems are too broad, the model can access information it should not. If data sources are compromised, the model will generate outputs based on manipulated context.
The model does not verify what it retrieves. It assumes it is correct. This turns the retrieval layer into one of the most important control points in the system.
Hallucinations
Hallucinations are often dismissed as a quality issue.
In practice, they are a security issue.
The risk is not that the model produces incorrect information. It is that the information appears credible. It is delivered with confidence and often in a format that looks authoritative.
In enterprise environments, this can lead to:
Incorrect decisions
Compliance issues
Misleading communication
And this is really hard to figure out especially if LLMs are your single point of source.
Resource Abuse
GenAI systems introduce a new kind of attack surface, that is, cost.
Because these systems are often usage-based, attackers can exploit them by generating high volumes of requests or triggering expensive operations. In this case, the system continues to function. It just becomes expensive and inefficient.
This makes detection harder, because the activity often looks like legitimate usage.
Additional GenAI Security Risks You Should Know
Some of the most significant risks are not technical in the traditional sense. They emerge from how these systems are used.
Deepfakes shift the problem from content to identity. When voice and video can be generated convincingly, traditional trust signals break down.
Shadow AI introduces risk through lack of visibility. Employees use tools outside approved environments, exposing data in ways that security teams cannot monitor.
AI-generated code accelerates development but often introduces insecure patterns. The output works, so it is trusted, even when it should not be.
These risks highlight a broader point. GenAI security is about behavior, both human and machine.
Real-World Examples of GenAI Security Threats
Support systems have been manipulated through prompt injection to reveal internal data. Internal assistants have surfaced sensitive information because retrieval controls were too broad. Early agent systems have executed unintended actions due to overly permissive access.
In each case, the system was functioning as designed. The failure was in how that behavior was understood and controlled.
Deepfake Scam
In one widely reported case, an employee at a Hong Kong firm joined what appeared to be a routine internal video call with senior leadership. Everyone on the call looked and sounded exactly like their colleagues. The conversation aligned with ongoing work. There was nothing obviously suspicious. Based on that, the employee approved a series of transfers worth over $25 million. It was only after the fact that it became clear that every participant on that call had been generated using AI.
There was no breach in the traditional sense. No credentials were stolen. No system was compromised. The attack worked because it bypassed technical controls entirely and operated at the identity layer. The employee trusted what they saw and heard, and the system had no way to challenge that trust.
This is what makes deepfake scams fundamentally different. They exploit how humans validate authenticity. As these techniques improve, the question shifts from “is this secure?” to “can we trust what we’re seeing at all?”
Phishing Scams
In 2023, Reddit disclosed a security incident where employees were targeted through a phishing campaign impersonating internal IT systems. The attacker sent messages that looked like legitimate security alerts and directed employees to a fake login portal. Because the request aligned with internal workflows, an employee entered credentials along with two-factor authentication tokens, giving the attacker access to internal systems and data.
In parallel, there has been a rise in voice-cloning phishing scams where attackers impersonate executives to request urgent financial actions. In documented cases reported by the FTC and multiple security firms, employees transferred funds after receiving calls that sounded identical to senior leadership, often under time pressure.
What has changed is the quality of execution. Messages now reflect real context, making them significantly harder to question in the moment.
GenAI Security Risks in Enterprise Environments
GenAI risks become significantly harder to manage in enterprise environments, not because the risks are different, but because the systems are more interconnected and the consequences are higher.
In most organizations, AI sits across internal tools, SaaS platforms, and workflows used by multiple teams. Data flows across these systems, often in ways that are not fully visible or controlled.
That makes it difficult to reason about where sensitive information is exposed and how AI systems are actually behaving in production.
Data Leakage via Employees
One of the most common entry points for risk is not the system itself, but how employees use it.
Employees regularly interact with AI tools using real data. This includes customer information, internal documents, financial data, and operational context. The intent is usually productivity, summarization, drafting responses, or getting quick insights. The problem is that these interactions often happen without clear boundaries on what data should or should not be shared.
When employees use external AI tools or even internal systems without strict access controls, sensitive information can unintentionally flow into prompts, retrieval systems, or outputs. In some cases, this data may be stored, logged, or reused in ways that are not immediately visible.
SaaS and AI Integrations
As AI capabilities are embedded into SaaS platforms, the attack surface expands in less obvious ways.
Most enterprise environments rely on a stack of interconnected tools, CRM systems, support platforms, collaboration tools, and internal dashboards. AI is increasingly integrated into these systems to automate tasks, generate insights, and streamline workflows. While this improves efficiency, it also creates new pathways for data access and movement.
Each integration introduces a new layer of trust. An AI system connected to multiple tools can pull data from one system, process it, and push it into another. If permissions are not tightly scoped or if integrations are not properly monitored, this can lead to unintended data exposure or misuse.
The complexity comes from the fact that no single system owns the full flow. Data moves across boundaries, and visibility is often fragmented. This makes it difficult for security teams to understand how AI-driven interactions are actually behaving end to end.
Compliance Risks
As regulatory frameworks around AI continue to evolve, compliance is becoming a critical concern for enterprise adoption.
Organizations are increasingly expected to demonstrate not just that their systems are secure, but that they are governed, auditable, and accountable. This includes understanding how data is used, how decisions are made, and how risks are managed across the AI lifecycle.
GenAI systems make this more challenging because of their probabilistic nature. Outputs are not always predictable, and decision-making processes are not always transparent. Without proper controls, it becomes difficult to explain why a system produced a certain output or how it handled sensitive data.
This creates exposure across multiple fronts, from data protection regulations to industry-specific compliance requirements. In many cases, the risk is the inability to demonstrate control when it matters.
How to Mitigate GenAI Security Risks
Mitigating GenAI security risks is less about adding a single control and more about building layered defenses across how the system behaves end to end. These systems are dynamic, which means security cannot rely on static checks or one-time validation.
You need controls at three levels: how inputs and outputs are handled, how systems are governed, and how behavior is tested and monitored over time.
Technical Controls
At the technical layer, the goal is to reduce how easily the system can be manipulated and limit the impact when it is.
Input and output filtering is the first line of defense. This is not just about blocking obvious malicious inputs, but about identifying patterns that indicate attempts to override instructions, extract sensitive data, or trigger unintended behavior. On the output side, it is equally important to validate what the model produces before it is returned or used downstream. Without this, unsafe or sensitive information can move through the system unnoticed.
Prompt isolation addresses a more structural issue. In many GenAI systems, system instructions, user inputs, and retrieved data are combined into a single context. That is what makes prompt injection possible. Isolating system-level instructions and enforcing clear boundaries between trusted and untrusted inputs reduces the chances of those instructions being overridden or manipulated.
Rate limiting plays a different role. It is less about correctness and more about control. By limiting how frequently systems can be queried or how intensively they can be used, you reduce exposure to abuse, whether that is data extraction attempts or cost-based attacks. It also creates friction for attackers trying to probe the system at scale.
Individually, these controls are not enough. Together, they create constraints that make the system harder to influence and easier to manage.
Governance Controls
Technical safeguards only work if they are supported by clear governance.
AI usage policies define how these systems should be used across the organization. This includes what data can be shared, which tools are approved, and what kinds of outputs can be relied on. Without this, employees will use AI in ways that optimize for speed, not security, often exposing sensitive data without realizing it.
Vendor risk assessment becomes critical as organizations rely more on third-party models, APIs, and tools. Each external dependency introduces risk, whether it is through data handling practices, model behavior, or integration points. Evaluating these vendors is not just about compliance checklists. It is about understanding how they handle data, what visibility you have into their systems, and how failures are managed.
Governance is what connects individual controls into a system that can be understood, enforced, and audited. Without it, even well-designed technical measures tend to break down in practice.
Advanced Strategies
As GenAI systems become more central to operations, mitigation needs to move beyond basic controls into continuous evaluation.
Red teaming is one of the most effective ways to do this. Instead of assuming the system behaves as intended, you actively test how it responds under adversarial conditions. This includes attempts to bypass safeguards, manipulate outputs, and trigger unintended actions. The goal is to understand how the system fails.
AI security monitoring extends this into production. Once systems are live, behavior can change based on usage patterns, data shifts, or new integrations. Monitoring helps detect anomalies, misuse, and emerging risks in real time. It provides visibility into how the system is actually being used, not just how it was designed to behave.
This is where most organizations struggle. Security is treated as a setup task, not an ongoing process. With GenAI, that approach does not hold. The system evolves, and security has to evolve with it.
Future of GenAI Security (2026 & Beyond)
The direction of GenAI is clear. Systems are becoming more autonomous, more integrated, and more critical to business operations. That will continue to reshape how security needs to be approached.
Agentic AI risks will become more prominent as models move from generating outputs to executing tasks. As agents gain access to tools, workflows, and external systems, the impact of incorrect or manipulated behavior increases. The focus will shift from what the model says to what it is allowed to do.
At the same time, an AI versus AI security dynamic is emerging. Attackers are already using AI to generate more convincing phishing attempts, automate reconnaissance, and scale attacks. Defenders will increasingly rely on AI to detect patterns, simulate attacks, and respond in real time. This creates an arms race where both sides are operating with similar capabilities.
Regulation trends will also play a larger role. Frameworks around AI governance, accountability, and risk management are evolving quickly. Organizations will need to demonstrate not just that their systems are secure, but that they are explainable, auditable, and controlled. This will push security from being a technical concern to a broader operational requirement.
The common thread across all of this is continuity. Security will need to move from periodic reviews to continuous oversight.
GenAI Security Checklist
A practical way to assess your current posture is to step back and ask whether you have visibility and control across the system.
Here are 10 questions to consider:
Can you trace how data flows through your AI systems, from input to output?
Do you have clear boundaries between system instructions and user inputs?
Are agent permissions scoped tightly enough to prevent unintended actions?
Do you validate outputs before they are used in downstream systems?
Are your retrieval systems access-controlled and monitored?
Do you have visibility into how AI systems interact with internal tools and APIs?
Can you detect abnormal behavior or misuse in real time?
Are third-party models and tools evaluated for risk before integration?
Do employees have clear guidance on how AI systems should be used?
Are your systems tested under adversarial conditions, not just normal usage?
If any of these questions are difficult to answer, there is likely a gap in your current setup.
Final Thoughts on GenAI Security Risks
If there’s one thing I’ve seen consistently, it’s this: most teams don’t have a tooling problem, they have a visibility problem.
GenAI systems are already in production. They’re connected to internal data, external tools, and increasingly, real workflows. But most teams still don’t fully know how these systems behave once they’re live. They assume guardrails are working. They assume access is controlled. They assume outputs are safe.
That assumption is where things start to break.
The reality is, GenAI security isn’t something you “set up” once. It’s something you continuously test, observe, and enforce. Especially as systems become more agent-driven and start taking actions across environments.
This is exactly where Akto fits in.
Akto is built for this new layer, securing AI agents and MCP-driven workflows where most of the real risk now exists. Instead of relying on static checks or one-time reviews, it continuously tests how your AI systems behave in practice. It helps you identify prompt injection vulnerabilities, unsafe tool usage, data exposure risks, and gaps in how agents interact with your systems.
More importantly, it gives you visibility. Not just into your APIs or infrastructure, but into how your AI is actually making decisions and taking actions in production.
Because at this point, the biggest risk is not that your system gets hacked. It’s that your system behaves in ways you didn’t anticipate, and you don’t catch it in time.
Akto helps close that gap. It gives you a way to move from assumption to validation, from static security to continuous control. Book AI Security Demo today!
If your AI systems are interacting with real data and real workflows, you need that layer. Otherwise, you’re operating without a clear view of your actual risk surface.
Important Links

Experience enterprise-grade Agentic Security solution