AI Security: Risks, Threats & Best Practices for LLMs (2026)
Explore the 2026 AI security threat landscape: Prompt injection, GenAI risks, and LLM vulnerabilities. Learn best practices to secure your AI systems.

Sucharitha

AI security was just a niche concern a few years back. But we’ve long passed the stage.
In 2026, LLMs can run complex human-like tasks, such as writing production code, running customer support queues, and summarizing business contracts.
Along with tools like ChatGPT, enterprise adoption of agentic AI changed how organizations approach automation and decision-making.
Unfortunately, AI security hasn’t kept pace, and traditional practices no longer make the cut.
Unlike conventional systems, LLMs interpret natural language dynamically, combine context sources at runtime, and may trigger automated downstream actions. So, if your organization is securing AI the same way it secures a REST API, you're already behind.
In this blog, we’ll uncover the AI security threat landscape and explore how to tackle the looming challenges.
What is AI Security?
AI security is the practice of protecting artificial intelligence systems from manipulation, misuse, and compromise. That includes the models themselves, the data they run on, the data they expose, and the actions they take.
Securing an AI system means protecting a dynamic non-convetional system that’s capable of interpretation, code execution, API calls, and agent orchestration. Clearly, AI security is a stack of problems where data integrity, output validation, access control, threat detection, and governance are at stake.
Core Principles of AI Security
A few fundamentals behind every serious AI security program are:
Assuming the model can be manipulated: An input to an LLM is a potential attack vector.
Least privilege: Applies to agents as AI agents should only have access to what they need to complete each task.
Visibility before control: You cannot secure what you cannot see. Every model, every integration, every prompt flow needs to be tracked and documented before it can be governed.
Security is continuous: AI security is an ongoing operational practice, not a one-time audit.
Key Pillars of AI Security
The six main pillars of AI security:
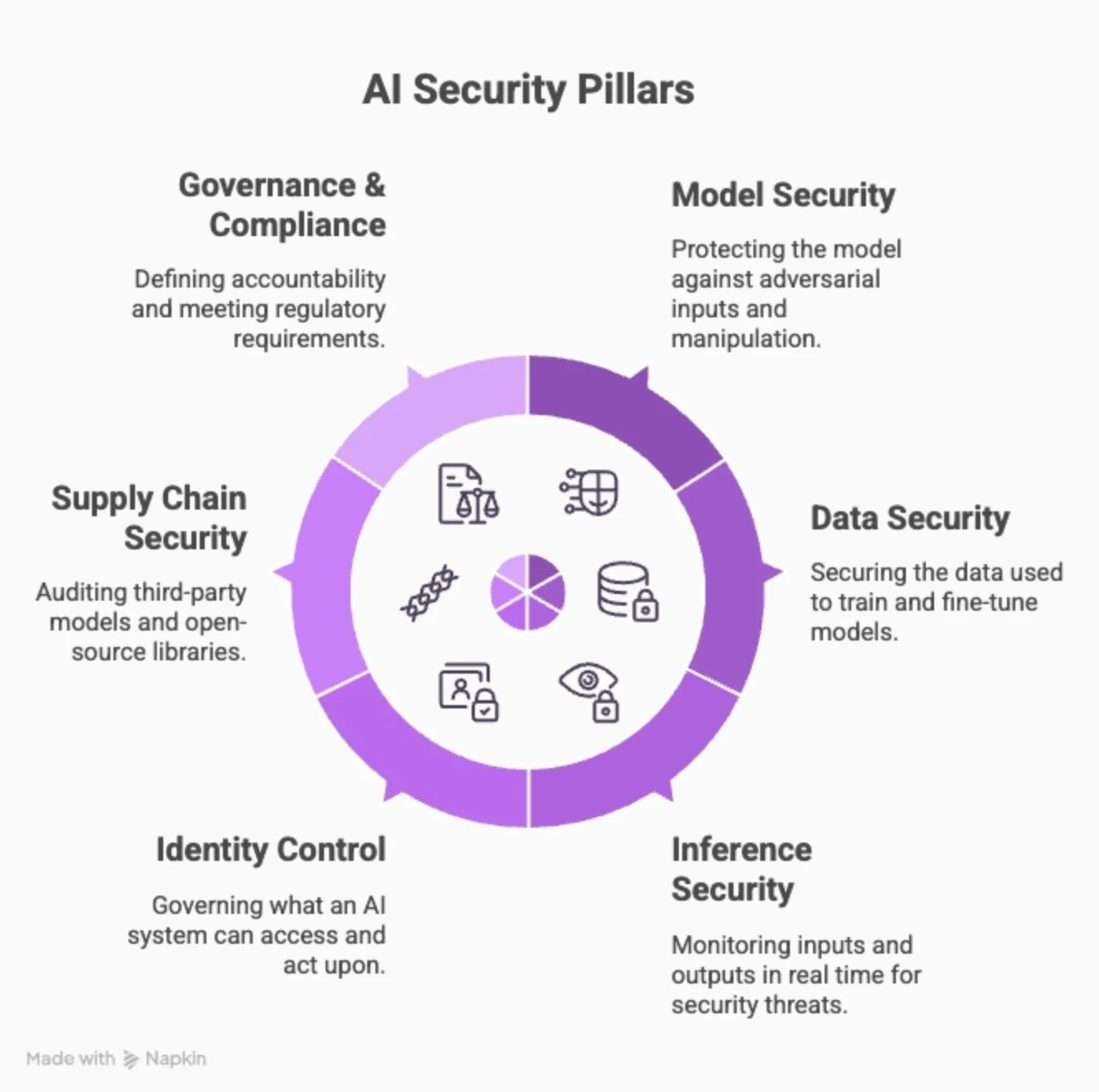
1. Model Security: Protecting the model itself against adversarial inputs, extraction attacks, and manipulation of model behavior through training-time or inference-time interference.
2. Data Security: Securing the data used to train, fine-tune, and augment models.
3. Inference & Runtime Security: Monitoring what goes in and what comes out in real time. This is where prompt injection detection, output filtering, and LLM firewalls operate.
4. Identity & Access Control: Governing what an AI system can access and act upon. Applies equally to user-facing models and autonomous agents operating inside enterprise environments.
5. Supply Chain Security Auditing third-party models, open-source libraries, plugins, and pre-trained components.
6. Governance & Compliance Defining accountability for AI decisions, meeting regulatory requirements (EU AI Act, NIST AI RMF), and maintaining audit trails.
Why AI Security is Critical in 2026
Here’s what the latest numbers have to tell about AI security’s urgency in 2026 and beyond:
69% of organizations have already deployed AI agents in real-world environments, rapidly expanding the enterprise attack surface.
Only 21% of enterprises maintain a complete inventory of AI agents and MCP connections, creating major visibility gaps.
79% of organizations lack governance policies for AI agent permissions and monitoring, increasing the risk of unauthorized access and untracked AI behavior.
AI now drives 83% of breaches, per Gigamon's 2026 survey of 1,000+ global security leaders.
1 in 8 companies report breaches now linked directly to agentic AI systems.
These trends show how most security teams are still catching up, as attackers continue to scale attacks with automation and AI.
AI Security Threat Landscape
The AI security threat landscape is split across the following vulnerabilities and threat vectors:
Model and Data Vulnerabilities
Vulnerabilities in AI are often invisible to standard security tooling and surface only during inference time.
A few top ones include:
Data poisoning: Happens at training time. Attackers inject malicious or manipulated data into a training dataset, causing the model to learn corrupted patterns.
Model inversion and extraction: let attackers reverse-engineer a model's training data or replicate its behavior through repeated querying. This exposes proprietary data and intellectual property without even touching the infrastructure directly.
Adversarial inputs: Small, deliberate perturbations in input can produce wildly incorrect or harmful outputs.
Incorrect output handling: When model outputs are passed directly into code interpreters, browsers, or system calls without validation, a poorly generated response is a great cause of concern.
Agentic AI and LLM-Specific Threats
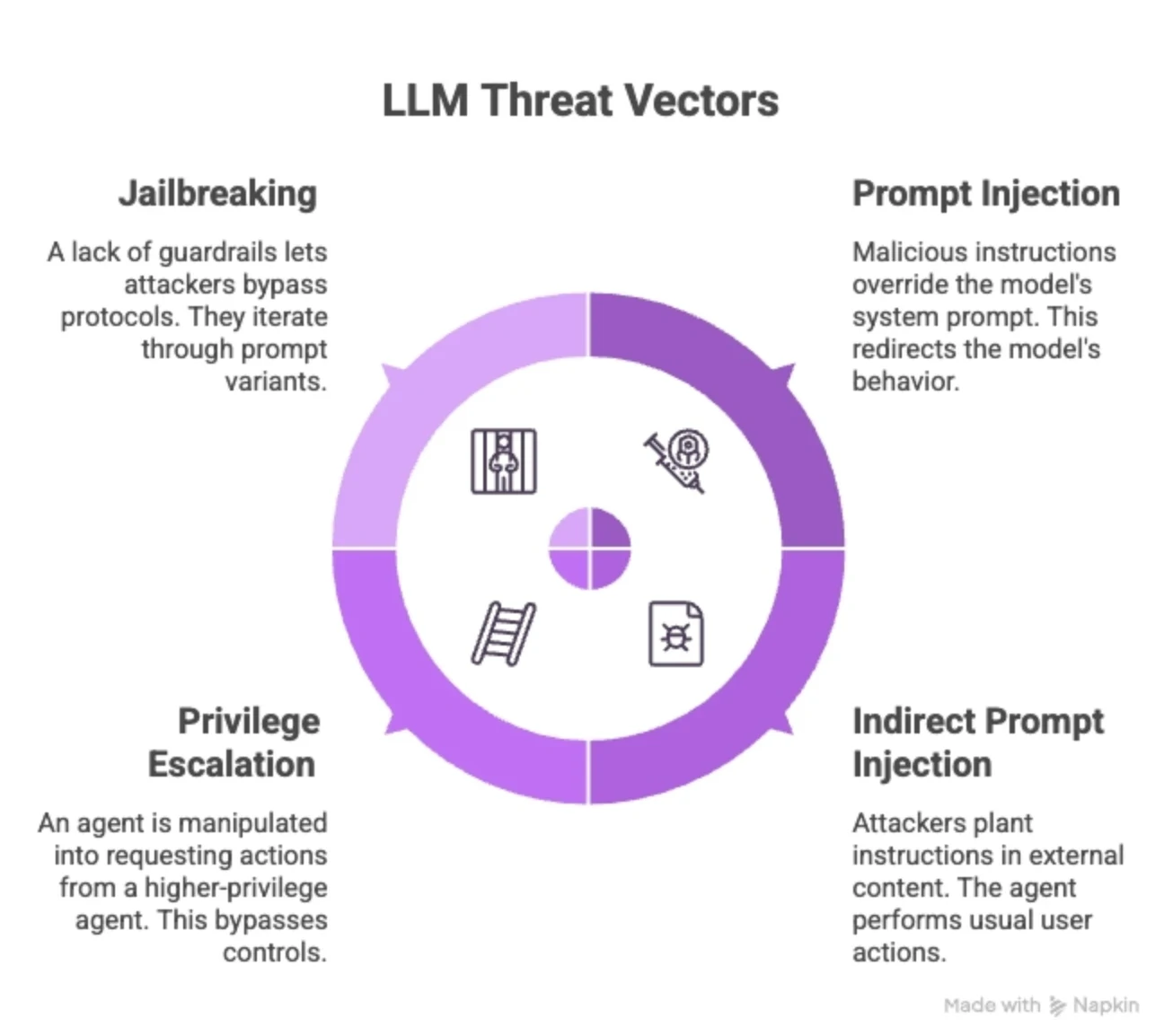
The shift to LLMs being used as autonomous actors has opened up several critical threat vectors:
Prompt injection: Malicious instructions hidden in user inputs, documents, or tool responses override the model's system prompt and redirect its behavior.
Indirect prompt injection: The attacker doesn't need access to the user interface. They plant instructions in external content, the agent will eventually perform the usual user actions.
Privilege escalation across agents: An agent can be manipulated into requesting actions from a higher-privilege agent, thus bypassing the controls.
Jailbreaking: A lack of guardrails lets attackers iterate through prompt variants and bypass protocols.
Supply Chain and Shadow AI Risks
Most organizations inherit risk from every model, library, plugin, and dataset they consume:
Malicious models in public repositories: A fast-growing supply chain threat, where malware is hidden in public model and code repositories.
Third-party plugins and tool integrations: An insecure plugin connected to your email, CRM, or cloud environment could be the victim of an attack the moment the model is compromised.
Shadow AI: Between one-fifth and one-third of employees use AI outside the influence and governance of the IT function. Security teams are trying to govern AI systems that they have no inventory of.
Adversarial Attacks and Input Manipulation
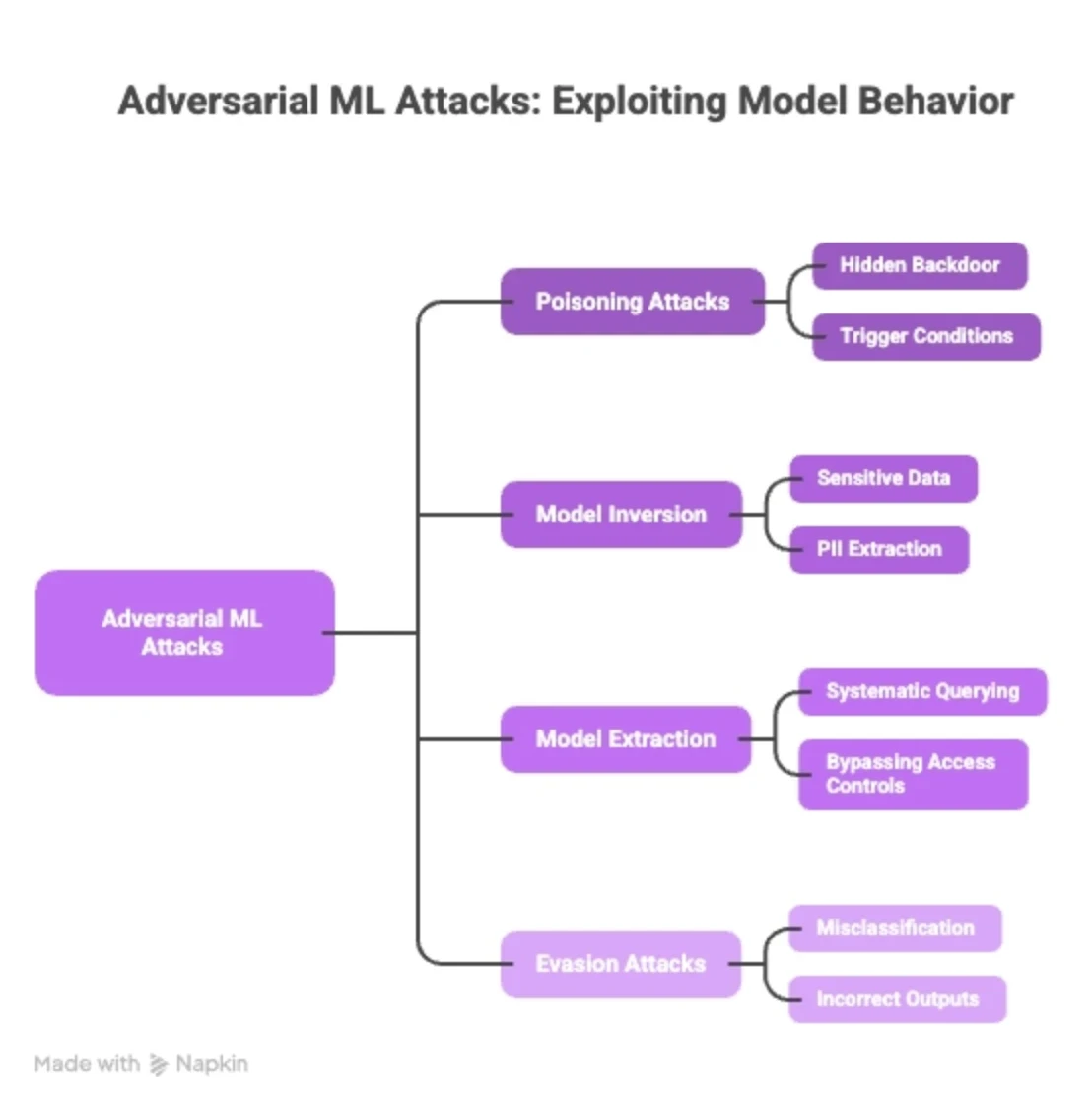
Adversarial Machine Learning Attacks
Adversarial ML attacks exploit the fundamental way models learn. The attack surface is the model's behavior itself.
Poisoning Attacks: Malicious samples are introduced into training data, embedding a hidden backdoor that activates only under specific trigger conditions. The model passes testing cleanly and fails silently in production.
Model Inversion: Sensitive training data is reconstructed through repeated querying of model outputs. Attackers can extract PII, proprietary records, or confidential information without ever accessing the training set directly.
Model Extraction: A proprietary model is replicated by systematically querying it and training a copy on its outputs. This bypasses access controls with no infrastructure access required.
Evasion Attacks: Inputs are manipulated at inference time to force the model into misclassification or incorrect outputs.
Prompt Injection and Jailbreak Techniques
Prompt injection attacks and jailbreaking are the most actively exploited AI attack techniques in production systems today:
Direct Prompt Injection: Malicious instructions embedded in user input override the model's system prompt, redirecting its behavior. In agentic systems, this translates directly into real-world actions, such as sending emails, querying databases, or calling external APIs.
Indirect Prompt Injection: The attacker plants malicious instructions in content that the model will retrieve and process, such as a webpage, a PDF, an email, or a tool response. The users are kept in the dark, while the model executes the payload as if provided legitimate access.
Jailbreaking: Safety constraints are bypassed through role-playing frames, token manipulation, or multi-turn context shifting. Bypass techniques evolve continuously against each new model version.
AI Security Posture Management (AI-SPM)
AI Security Posture Management is the practice of continuously discovering, assessing, and enforcing security controls across an organization's entire AI footprint.
Since AI systems are opaque, fast-moving, and often deployed without security team involvement, AI-SPM closes this gap by making the AI environment visible, governable, and auditable.
What it involves:
AI Asset Discovery and Inventory
You cannot secure what you don't know exists. AI-SPM starts with building a complete, continuously updated inventory of every AI asset in the environment.
Model Inventory: Catalog every model in use across the organization, including foundation models, fine-tuned variants, and third-party APIs. Track version, provider, deployment context, and data access scope.
Integration Mapping: Identify every system the AI touches, i.e., databases, SaaS tools, internal APIs, email, and code repositories.
Shadow AI Detection: Actively scan for unsanctioned AI tools being used outside IT governance.
Data Flow Visibility: Track what data enters models, where outputs go, and whether sensitive data is being processed by systems that are not supposed to handle it.
Policy Enforcement, Guardrails, and Access Control
AI-SPM translates security policies into active controls at the model and agent level:
Least Privilege for AI Agents: Every agent should operate with the minimum permissions required for its task. Broad tool access, memory reach, and API permissions are the primary contributors to blast radius when an agent is compromised.
Input and Output Guardrails: Enforce controls on what enters a model and what it returns. This includes prompt injection detection, content filtering, PII redaction, and output validation before responses are acted upon or surfaced to users.
Role-Based Access to AI Systems: Define who can deploy models, modify system prompts, connect integrations, and access inference logs. Treat AI system configuration as privileged access, not a developer convenience.
Runtime Policy Enforcement: Policies need to apply at inference time, not just at deployment. Real-time monitoring of model behavior, tool calls, and agent actions ensures controls hold as usage evolves.
Governance and Compliance
Governance gives organizations accountability over their AI systems. Compliance ensures that accountability meets regulatory and legal obligations.
Here’s what AI-SPM entails:
Audit Trails: Log model inputs, outputs, tool calls, and agent actions.
Regulatory Alignment: Map AI deployments against applicable frameworks, including the EU AI Act, NIST AI RMF, ISO 42001, and sector-specific requirements like HIPAA or SOC 2.
AI Risk Register: Maintain a living register of AI-related risks tied to specific models, use cases, and data types. Each entry should have an owner, a risk rating, and a remediation status.
Accountability Ownership: 73% of organizations report internal conflict over who owns AI security. Governance frameworks need to assign clear accountability across security, legal, data, and product teams before an incident occurs in real-time.
Best Practices for Securing AI Systems
Security for AI systems isn't a checklist you run once at launch. It's a set of practices that need to operate continuously across the model lifecycle, from development through production:
Secure SDLC for AI and LLM Applications
AI applications need security built into every stage of development:
Threat Model Before You Build: Identify attack vectors specific to your AI use case before writing a line of code.
Training Data Validation: Audit datasets before training or fine-tuning. Check for poisoned samples, biased distributions, and data sourced from untrusted pipelines.
Prompt and System Prompt Review: Treat system prompts as security-sensitive configuration. Test them against known injection patterns, and version-control every change.
Red Team Before Release: Run adversarial testing against every AI application before it goes live. Test for prompt injection, jailbreaks, data leakage, and unexpected tool-use behavior.
Dependency and Model Supply Chain Checks: Scan third-party models, libraries, and plugins before integrating them.
Access Control and Least Privilege
Grant AI agents only the tools, APIs, and data access they need for their specific task. For example, a coding agent doesn't need access to the CRM.
Assign distinct service identities to AI agents and models rather than sharing credentials across systems. Separate identities enable precise access logging, clean revocation, and clear attribution when something goes wrong.
Continuous Monitoring and Drift Detection
Models don't stay static. Their behavior keeps shifting as inputs evolve, integrations change, and new attack techniques emerge. Continuous monitoring is the only way to keep pace.
Start by logging everything during inference, including inputs, outputs, tool calls, and agent actions. This is the baseline for both real-time detection and post-breach scenarios.
Treat prompt changes, model version updates, and new tool integrations as security events.
AI Security Testing and Runtime Protection
AI security testing isn’t about finding bugs. It’s about finding ways an AI model can be manipulated, mishandled, and misused. The following three methods help test and build a secure AI system while offering runtime protection:
Automated Red Teaming for AI Systems
Automated red teaming uses adversarial prompts, fuzzing techniques, and AI-generated attack scenarios to stress-test models at scale.
It probes for prompt injection vulnerabilities, jailbreak susceptibility, data leakage, and unsafe tool-use behavior before attackers find them first.
However, keep note that red teaming isn’t a pre-launch phase. It needs to run continuously, especially after model updates, prompt changes, or new tool integrations.
Runtime Protection and Real-Time Threat Detection
Runtime protection sits between the user and the model, inspecting inputs before they reach the model and outputs before they reach the user.
This is where prompt injection attempts are caught, and responses that violate policy are blocked before they cause damage.
For agentic systems, runtime protection extends to tool calls and agent actions. Every API call an agent makes, every file it reads, and every external system it touches is a point where anomalous behavior can be detected and stopped before it becomes a breach.
Real-World AI Security Case Studies
Below are some recent incidents that show how AI security failures happen in production environments:
1. Prompt Injection in Multi-Agent Systems
Slack AI was found vulnerable to a combination of RAG poisoning and social engineering.
Poisoned messages placed in accessible Slack channels influenced the AI's behavior when processing queries, causing it to extract and leak information from private channels through tool calls disguised as legitimate operations.
The attack exploited the exact feature users trusted most, i.e., AI reading channel history for context.
2. Shadow AI and Data Leakage Incidents
Within weeks of Samsung's semiconductor division lifting its internal ban on ChatGPT, engineers leaked confidential data on three separate occasions.
One major incident happened when it was noticed how every prompt sent to ChatGPT at the time was potentially retained by OpenAI for model training, meaning Samsung's proprietary code and internal discussions were surfaced in response to other users' queries.
Key Lessons Learned
Samsung allowed ChatGPT use with an informal memo advising caution. Three leaks followed in under 20 days. A policy without an enforcement mechanism is a waste of time.
A browser AI that can only summarize is low-risk. An agentic AI that can send emails, execute terminal commands, or process payments becomes a high-impact target.
Logging is not optional.
The relevant question in shadow AI is whether controls exist to prevent exposure regardless of intent.
Future of AI Security
Here’s how the AI security rules and defenses are changing:
Emerging Regulations and Compliance Standards
Regulation is no longer theoretical.
High-risk AI systems now require mandatory conformity assessments, human oversight mechanisms, and documented risk management processes before deployment.
The US, UK, Singapore, and over 25 other countries have introduced or enacted AI-specific legislation since 2023.
Evolving AI Attack Techniques
Attackers are evolving faster than AI. There can be a spike in incidents around automated jail breaking, cross-agent manipulation, model supply chain attacks, and AI-generated phishing and social engineering.
The Shift Toward Continuous AI Security
AI security is converging with DevSecOps. The teams that treat it as a lifecycle practice rather than a pre-launch checklist will be the ones that stay defensible as the threat landscape keeps shifting.
The organizations who understand the urgency are already building AI-specific detection pipelines, behavioral monitoring at inference time, and automated red teaming into their standard security operations.
Final Thoughts: Building Secure and Resilient AI Systems
AI models are getting more capable, and agentic AI is getting more autonomous.
The quick advancements have only surged the number of threat incidents and expanded the attack surface.
The best bet for every AI-forward organization is to AI security as an operational protocol and not a deployment checklist.
The fundamentals covered in this guide, from understanding the threat landscape to securing the model lifecycle and monitoring at runtime are not aspirational. They are the baseline for any organization running AI in production in 2026.
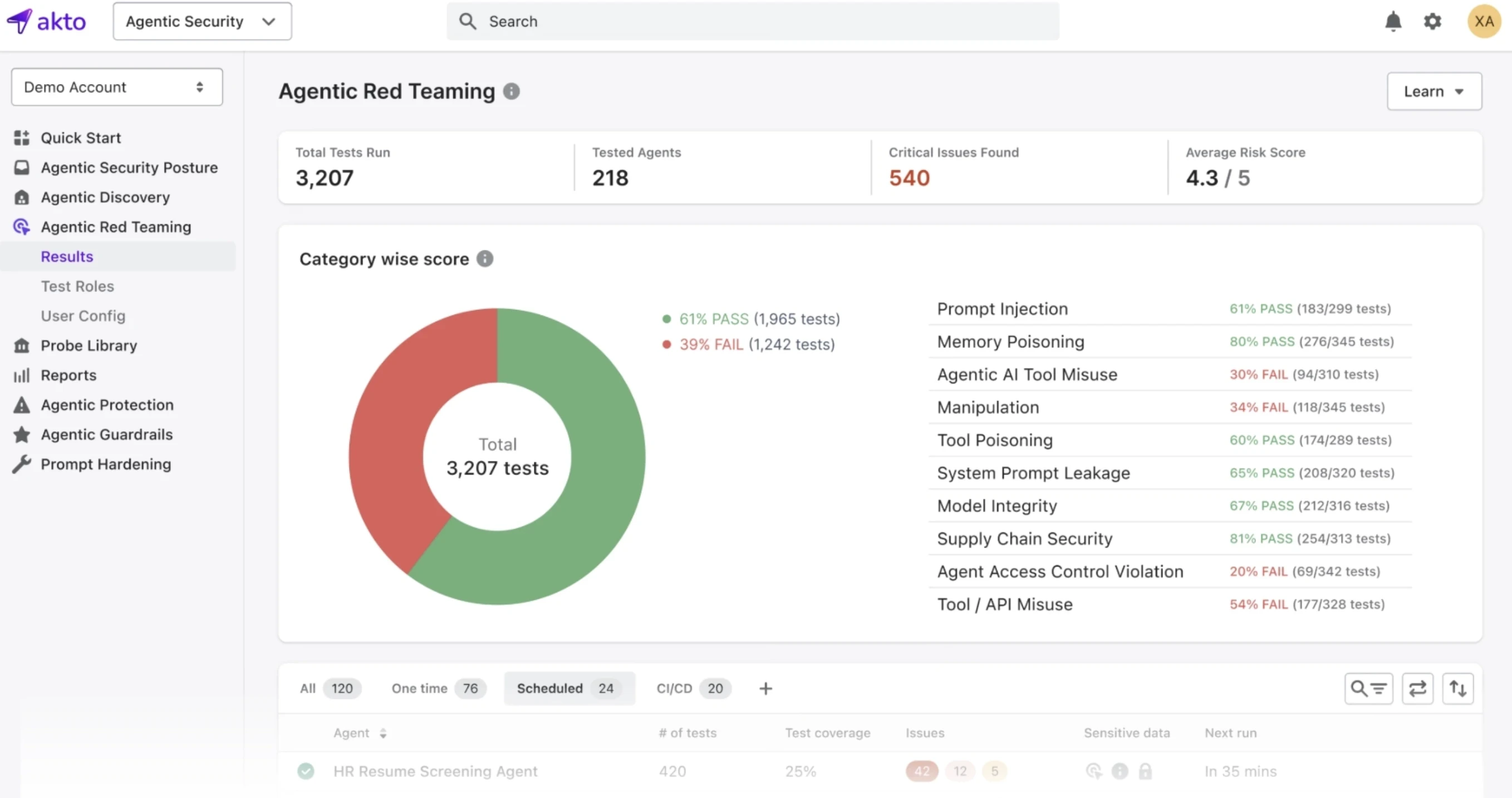
If you are building or securing LLM-powered applications, Akto gives you the visibility and testing infrastructure to find AI vulnerabilities before attackers do.
See how Akto helps secure your AI agents today!
Important Links

Experience enterprise-grade Agentic Security solution