5 Claude Agent Skills Risks Every CISO Should Know
Claude Skills introduces new supply chain, privilege escalation, and agent hijacking risks. Learn the top 5 security threats every CISO should understand.

Krishanu

The SKILL.md file is the new package.json. And it's already compromised.
Developers and business users trust Claude Skills the way engineers once trusted npm packages. Install a skill on Claude Code, claude.ai, or via the API. Extend the agent's capabilities. Ship faster.
But the parallels don't stop at convenience. They extend to the attack surface.
Over the past six months, security researchers have converged on the same finding: the Claude agent skills ecosystem carries systemic security risks that most organizations are not equipped to detect or mitigate. One major audit found 36.82% of skills contain security flaws. A large-scale analysis of 42,447 skills found 26.1% carry at least one vulnerability. OWASP formalized these risks into the Agentic Skills Top 10 (AST10) in March 2026.
Here are the five vulnerability categories every CISO should understand.
1. Ungoverned Skill Sprawl
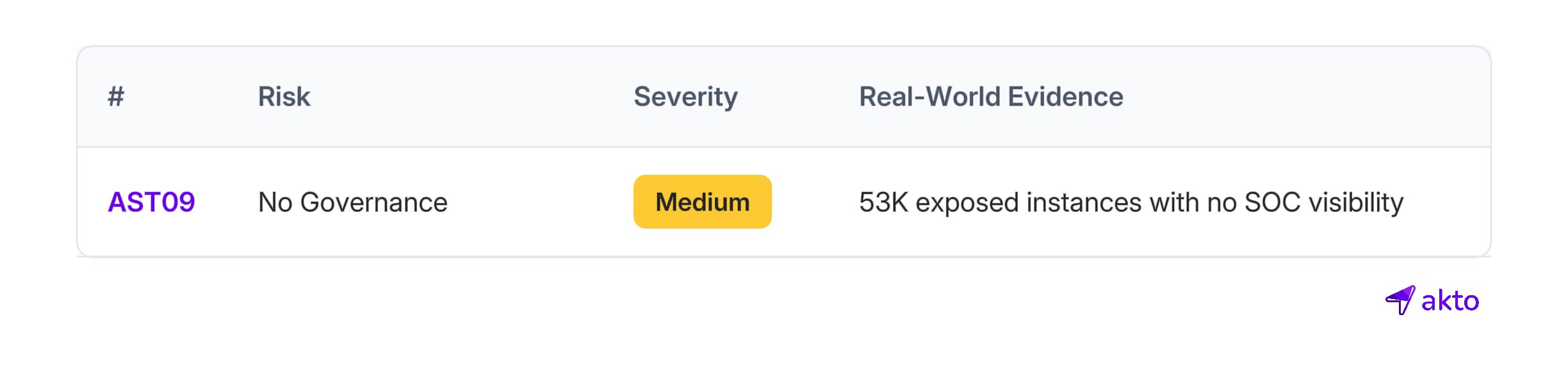
Before you can secure agent skills, you need to know they exist. Most security teams don't. (OWASP AST09)
Skills install silently into ~/.claude/skills/ directories on developer workstations via Claude Code, and load on demand when Claude detects a matching prompt. On claude.ai, non-technical employees add skills with a single click. No centralized registry. No MDM integration. No SIEM event when someone pulls a SKILL.md from GitHub.
When we deployed Akto Atlas in a customer's environment for the first time, it discovered 400+ agent skills on workstations that the security team had no idea existed.
Industry data corroborates the pattern: 53,000+ exposed agent instances with no SOC visibility, and employees deploying agents on corporate devices without organizational controls.
Without a skill inventory, every other security control is blind. You cannot enforce least privilege, scan for malicious payloads, or respond to incidents against an attack surface you haven't mapped.
2. Supply Chain Poisoning: Open Registries, Zero Vetting
Agent skill registries operate like early-era package managers: open submission, minimal vetting, no code signing, no provenance tracking. Anyone can publish a skill. Anyone can impersonate a trusted brand. And the same SKILL.md file flows across multiple registries without distinction.
The risk has two dimensions. First, intentionally malicious skills (OWASP AST01) distributed through registries: credential stealers, ransomware loaders, and data exfiltration tools disguised as productivity boosters. Second, upstream compromise, where repository-controlled configuration files function as an execution layer (OWASP AST02). Published CVEs confirm that simply cloning an untrusted project can trigger code execution and credential exfiltration before any consent dialog surfaces.
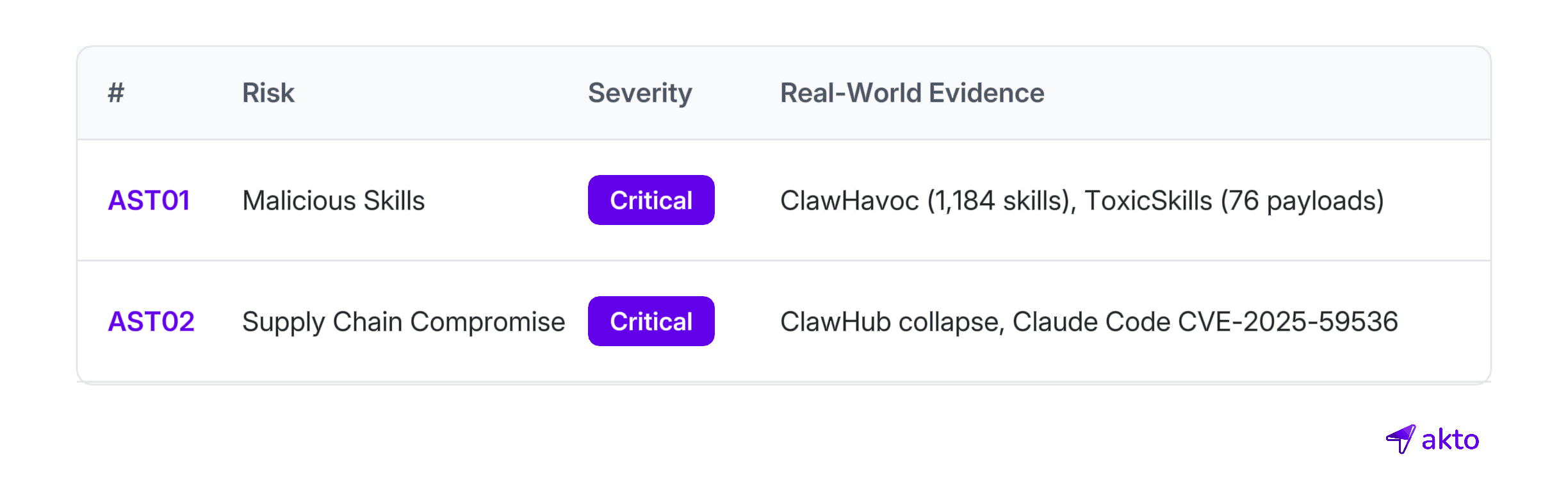
This is not hypothetical. One documented campaign saw 1,184 malicious skills flood a major registry across 12 publisher accounts. At peak infection, five of the top seven most-downloaded skills were confirmed malware.
3. Over-Privileged Execution: One Approval, Infinite Permissions
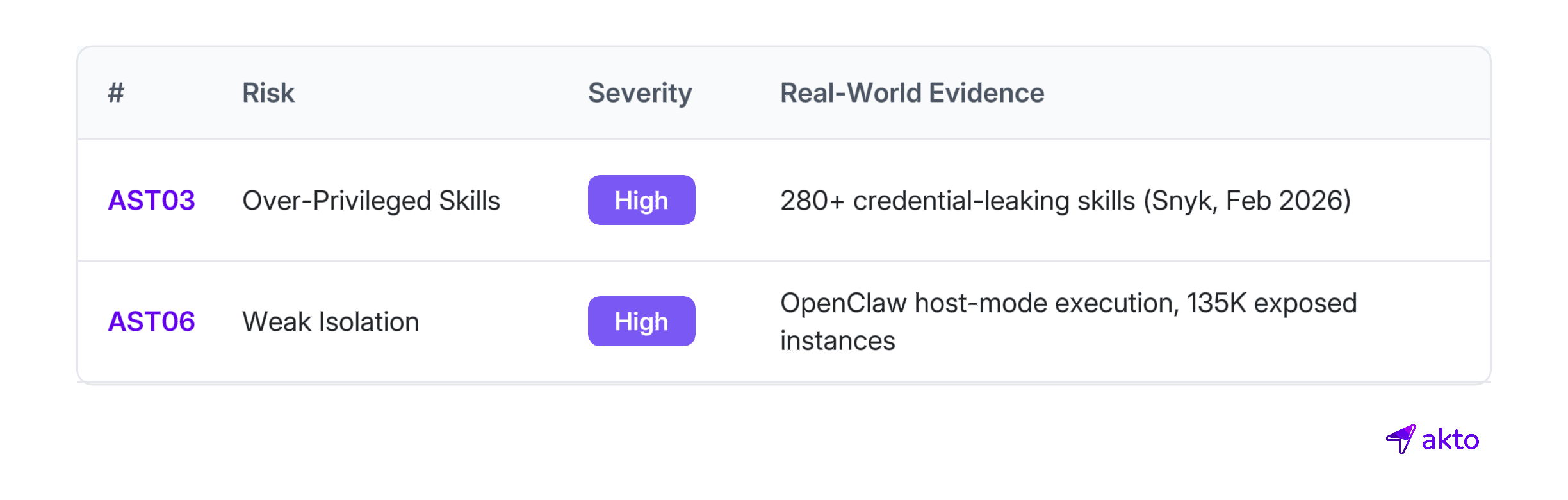
Skills inherit the agent's full runtime context (OWASP AST03). If the agent has access to a GitHub token, AWS credentials, or database connection strings, every installed skill inherits that access. There is no per-skill permission boundary in most deployments.
Audits have documented 280+ skills leaking API keys and PII through over-permissioned file and network access. But the bigger issue is isolation: skills run with host-level access rather than inside sandboxes (OWASP AST06). Once a skill receives approval, it can read/write files, download and execute additional code, and open outbound connections without further prompts.
Researchers call this the "consent gap." Users approve what they see, but hidden subprocesses operate under the same trust context. One proof-of-concept demonstrated a legitimate-looking skill delivering live ransomware through a single hidden helper function, all under the initial approval.
The convergence of private data access, untrusted skill instructions, and network egress capability is what makes this especially dangerous. Most production deployments satisfy all three conditions simultaneously.
4. Invisible Payloads: Markdown as an Attack Vector
Traditional supply chain attacks embed malicious code in executables. Agent skill attacks embed malicious instructions in Markdown (OWASP AST04).
Three lines of natural language in a SKILL.md file can instruct an agent to read ~/.ssh/id_rsa and POST it to an external endpoint. No eval(). No subprocess. No detectable code signature. Pattern-matching scanners looking for dangerous function calls miss these entirely.
The problem compounds when skills use dynamic context commands that execute shell commands at load time, before the model even processes the skill (OWASP AST08). When this happens, the AI's own safety reasoning is bypassed entirely. The model never gets a chance to refuse.

Behavioral studies confirm malicious skills split into two archetypes: Data Thieves exfiltrating credentials through silent network calls, and Agent Hijackers subverting agent decision-making through instruction manipulation. Both operate below the detection threshold of conventional code scanners.
5. Cross-Platform Portability: The Risk Travels With the File
The SKILL.md format works across Claude Code, claude.ai, OpenClaw, Cursor, and Codex CLI. That portability is powerful for adoption but devastating for containment (OWASP AST10).
A malicious skill published on one registry gets reindexed into others. A skill scanned as safe on one platform may behave differently on another where permission models differ, and security metadata is lost in transit. Without immutable version pinning, a previously clean skill can receive a malicious update that propagates silently across every platform that indexes it.
A CVE scored at 9.9 (CVSS) demonstrated that malicious websites could brute-force localhost connections to hijack local agent instances and push updates without user prompts. The attack surface is no longer a single registry or a single platform. It is the file itself.
The SKILL.md file is the new package.json. OWASP's Agentic Skills Top 10 framework provides the most comprehensive taxonomy of these risks to date, and the published audits provide clear evidence that the threat is already active. The question is whether security teams will act before the first enterprise-scale incident forces the conversation.

Experience enterprise-grade Agentic Security solution