AI Agent Security Solutions for Runtime Protection & Threat Detection
Explore AI agent security solutions for runtime protection, prompt injection defense, AI threat detection, guardrails, and zero-trust security.

Sucharitha

Today's AI agents book meetings, query databases, call APIs, write and execute code, and make decisions without waiting for human approval.
This shift is happening fast, and most security teams are still catching up.
AI agent security solutions exist to fill this gap.
Traditional tools like firewalls, SAST scanners, and WAFs were built for human actions, such as writing code and performing UI actions. They lack the framework to evaluate autonomous agents’ behaviours and fail to catch threats.
Securing agentic AI requires a fundamentally different approach.
An agentic AI security platform needs to operate at runtime, and not just at deployment. It needs to adapt continuously as agents learn, update, and encounter new inputs.
That means runtime protection for AI agents is the foundation, and not an optional layer.
In this guide, we walk through AI agent threat detection, core vulnerabilities of AI systems, and the modern threat landscape.
Understanding AI Agent Security: Definitions, Context, and Why It Matters
Security conversations about AI have shifted fast. A few years ago, it was about chatbots, and now it’s all about agents and LLMs.
This section builds the foundation on what AI agents actually are, how agentic workflows differ from traditional software, and why they expand the attack surface.
What Are AI Agents and Agentic Workflows?
An AI agent is a system that perceives inputs, reasons, selects actions, executes those actions through tools or APIs, observes the results, and decides what to do next without any human interference.
The agentic AI architecture has five core components:
LLM: It interprets goals, generates plans, decides which tools to invoke, and evaluates results.
Memory: Short-term memory holds the current task context, and long-term memory persists across sessions, allowing agents to retain preferences, learned patterns, and task history.
The orchestration layer: Coordinates multi-step execution by sequencing tasks, routing subtasks, and deciding when a goal is completed.
Tools and APIs: Decide how agents act. The breadth of tool access directly determines the blast radius of a compromised agent.
MCP integrations: Built on the Model Context Protocol, they allow agents to dynamically discover and connect to external services at runtime.
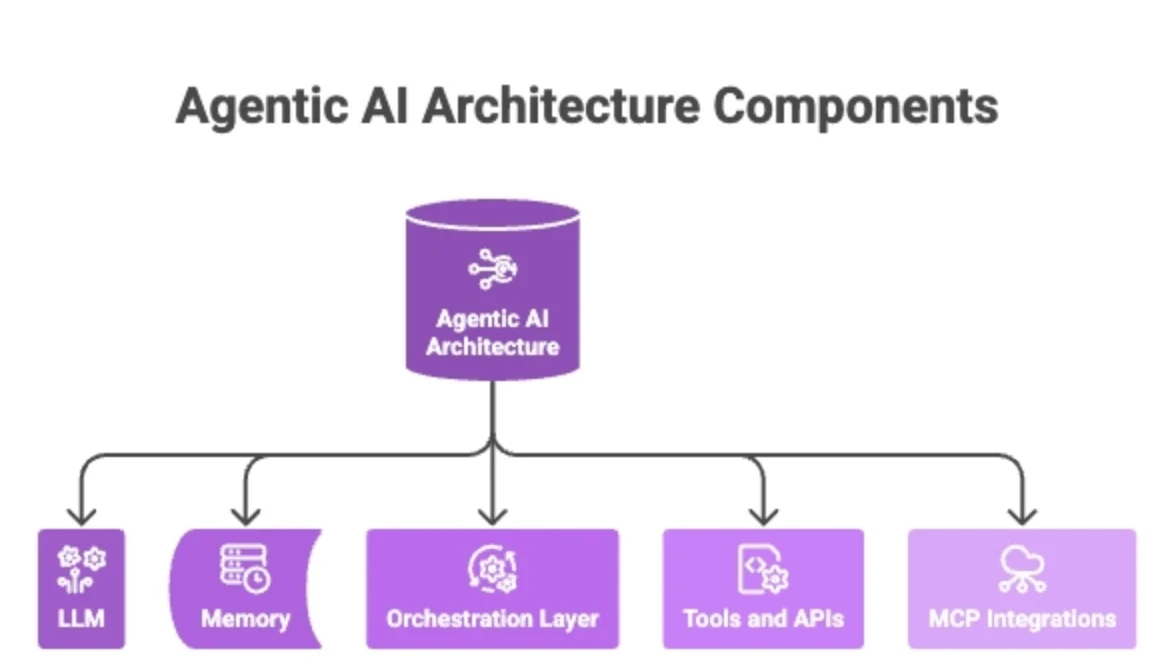
Agentic workflows emerge when these components operate in sequence across multiple steps. For example, a finance agent queries a database, reconciles it on spreadsheets, flags an anomaly, and files a ticket in a project management tool, all without asking for any human input.
Why Agentic AI Expands the Attack Surface
Traditional enterprise software follows deterministic paths. A given input produces a predictable output. Security teams can model the behavior, audit the code, and test the endpoints.
However, agentic AI never works this way.
An AI agent doesn't follow a fixed execution path. Two agents given identical starting conditions can take entirely different action sequences based on several conditions and contexts. Such a probability makes behavioral auditing challenging.
Also, multi-agent architectures can increase the attack surface as inter-agent messages often lack the validation controls applied to external API calls, further complicating AI agent threat detection.
The Modern Threat Landscape: Real-World Risks Facing AI Agents
AI agents don't operate in isolation. They read data, call APIs, write to databases, execute code, and communicate with other agents autonomously and at speed. This operational scope makes them primary targets for security attacks.
Below are the most common threat categories we deal with lately:
1. Prompt Injection and Goal Manipulation
Prompt injection is the most widely exploited vulnerability class in agentic AI systems.
It happens when an attacker crafts input that the agent interprets as instructions rather than data and manipulates its behaviour.
Direct prompt injection: Targets the agent's primary input channel. A user submits a request that contains hidden instructions in natural language or embedded in a document. The agent processes it as part of its task context.
Indirect prompt injection: The malicious instruction doesn't come from the user at all. It arrives through content the agent retrieves as part of its workflow. The agent has no way to distinguish between legitimate retrieved content and adversarial content without explicit AI agent guardrails.
Goal hijacking: Shifts the agent's objective mid-task. Rather than blocking the agent, the attacker redirects it.
Context manipulation: Works by corrupting the agent's working memory during a task. By injecting false context, for instance, altering tool outputs, faking prior steps, or manipulating history.
Cross-agent poisoning: Extends the attack to multi-agent systems. In an orchestrated pipeline, one agent's output becomes another agent's input. A compromised sub-agent can pass manipulated data or instructions upstream to an orchestrator, thus propagating the attack.
Malicious instruction chaining: Strings together multiple injections across a workflow. Each step appears legitimate, and the harm is only visible when the full chain executes.
2. Tool and Resource Abuse
Agentic AI systems use a wide range of tools, making tool abuse a major concern in enterprise deployments:
Unauthorized API access: Overly permissive configurations leave agents with access to endpoints they have no business reason to touch.
Tool misuse: The agent uses a permitted tool in an unpermitted way. For example, a document retrieval tool is used to enumerate sensitive files.
Excessive permissions: Agents provisioned with broad access for convenience can expand the blast radius of any compromise.
Autonomous transactions: Agents that can write to databases, submit forms, initiate payments, or send communications can cause real-world damage before any human reviews their actions.
Command execution abuse: Agents with shell or code-execution access are among the most dangerous when manipulated.
Third-party connector risks. MCP-enabled agents can discover and connect to external services dynamically, meaning accessible systems can expand the threat surface at runtime.
3. Memory and Data Poisoning
Long-term memory poisoning: An attacker who successfully injects malicious content into an agent's long-term memory affects subsequent tasks that draw on that memory.
Retrieval manipulation: By poisoning the documents, records, or embeddings that an agent retrieves, an attacker influences the agent's reasoning without ever touching its core instructions.
Sensitive data leakage: Agents with access to sensitive data sources can include that data in responses, logs, or outputs passed to other systems. When agents interact with external services, that data could be exposed.
Persistence-based attacks: An attacker who successfully plants instructions or corrupted data in an agent's memory, retrieval index, or tool configuration achieves persistent influence over that agent's future behavior.
Core Vulnerabilities in Agentic AI Systems
AI agents evolve through interactions, accumulate context, and make decisions shaped by inputs. That makes their vulnerability profile harder to monitor over time.
Two categories of vulnerabilities stand out:
Privilege Escalation and Identity Spoofing
Overprivileged agents: The most common starting point where agents are provisioned with broad permissions for convenience, creating unnecessary exposure from day one. AI agent posture management starts here by understanding what each agent can access and whether it actually needs that access.
Credential theft: A direct consequence of broad access. Agents often hold API keys, OAuth tokens, and service credentials. Those credentials, if exposed through prompt injection or memory leakage, hand an attacker the same access the agent has.
Identity impersonation: It occurs when one agent mimics another, especially in multi-agent systems where agents frequently accept instructions from peer agents without verifying the source.
Session hijacking: Targets active agent sessions by inserting into an ongoing session, where an attacker can redirect tasks mid-execution.
Supply Chain and Plugin Risks
AI agents connect to plugins, MCP servers, third-party APIs, and external orchestration layers. Every one of those connections is a potential entry point.
MCP connector risks: MCP discovery allows agents to find and connect to external services dynamically at runtime. That flexibility means an agent's effective tool surface can expand without an explicit configuration change.
Plugin compromise: A plugin an agent relies on can be modified, either through a compromised update pipeline or a malicious maintainer.
Third-party tool vulnerabilities: An agent that calls a vulnerable API inherits the risk of whatever that API exposes.
Orchestration trust issues: These surface when agents accept task instructions without verifying the chain of authority. A message that appears to come from a legitimate orchestrator may not be authentic.
Zero Trust and Least Privilege for AI Agents: Principles and Patterns
Agents cross boundaries, delegate to other agents, invoke external tools, and make decisions autonomously.
Zero trust for AI agents is the only architecture that accounts for how agents actually behave.
Here’s what it entails:
Microsegmentation and Context-Aware Controls
Identity and access for AI agents must be scoped to the session, not the system.
An agent authorized to read customer records for a support workflow has no business accessing financial data, even if both live in the same environment.
Dynamic authorization takes this further. Rather than granting permissions at deployment and leaving them static, context-aware policy engines evaluate each request against the agent's current task, role, and behavioral history.
Risk-aware policies and session-level access controls are what make enterprise AI security best practices operational rather than theoretical.
Every agent invocation carries a risk score. High-risk actions, such as large data reads, outbound writes, and code execution, require elevated justification before proceeding.
Dynamic Guardrails for Tool Calls and Prompts
Static guardrails break under the variability of agentic behavior. What agents need are runtime controls that evaluate intent and context.
Prompt validation intercepts inputs before the agent processes them, flagging patterns consistent with injection attempts or goal manipulation.
On the other hand, tool call monitoring operates at the execution layer. Every tool invocation is logged, evaluated against the agent's current task scope, and filtered if it falls outside expected behavior.
What’s necessary are AI agent guardrails, as they are context-aware moderation policies that can be updated as threat patterns evolve, without redeploying the agent.
Continuous Monitoring and Automated Red Teaming for Agentic AI
Securing agentic AI at runtime requires continuous probing and continuous observation via regular monitoring and automated red teaming:
Automated AI Red Teaming: Probe Libraries and Attack Simulation
AI red teaming for agentic systems is different from red teaming a web application.
You're probing the decision-making behavior of a system that responds differently depending on context, history, and input phrasing.
Adversarial prompt libraries give security teams a repeatable way to test how an agent responds to injection attempts, goal manipulation, and context corruption.
These libraries need to evolve continuously, as attack patterns that fail today may succeed after the next model update or prompt revision.
Many real attacks unfold across several exchanges.
Automated attack chaining simulates this by running sequences of inputs designed to build on each other, testing whether the agent's AI threat detection holds across a full conversation and not just the entry point.
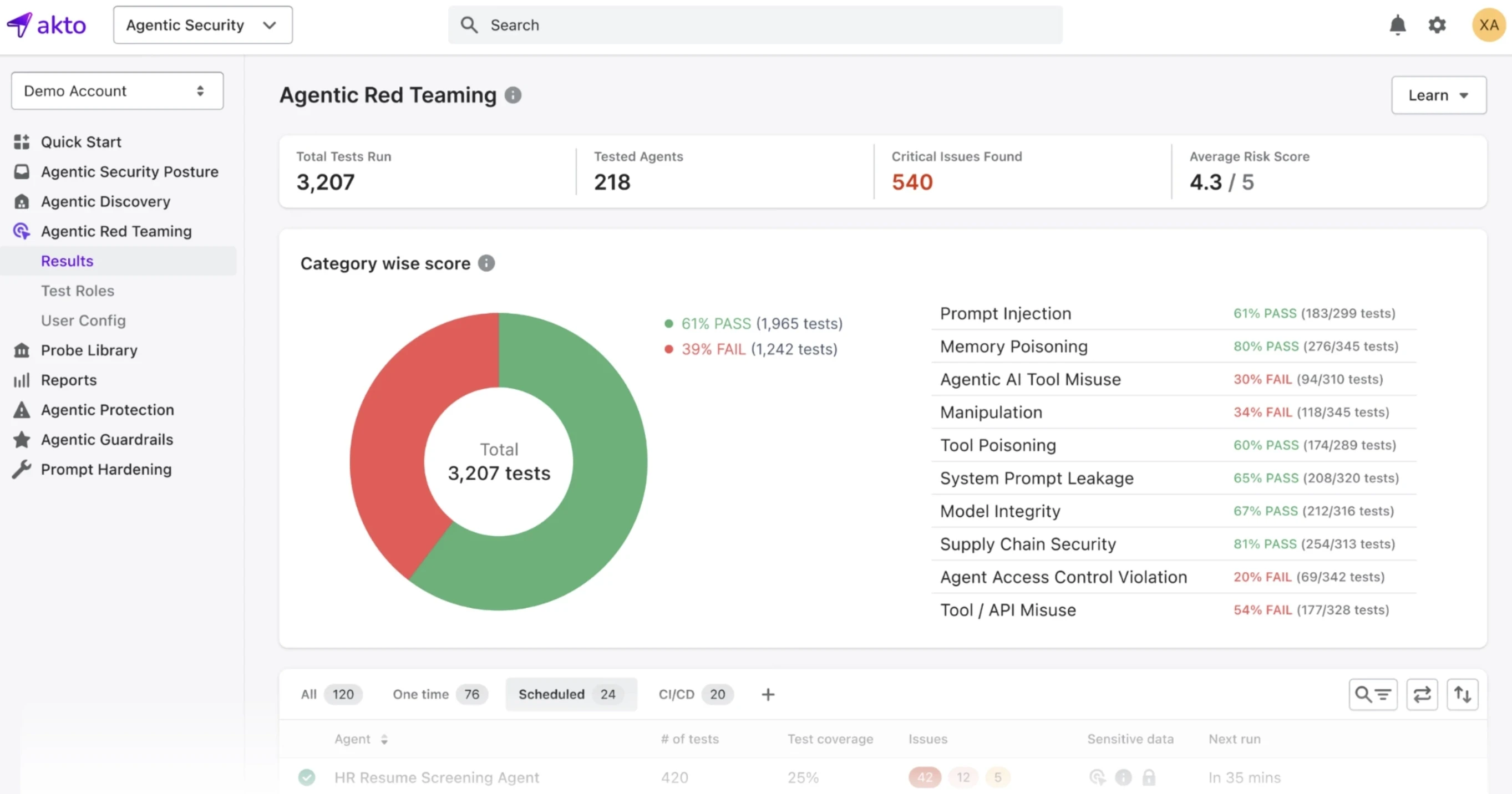
Runtime Drift Detection and Behavioral Analytics
Behavioral baselining establishes what normal looks like for each agent. Without a baseline, anomaly detection has nothing to measure against.
Runtime anomaly detection compares live agent behavior against that baseline continuously.
An agent that starts accessing data sources outside its normal pattern, invoking tools in unusual sequences, or producing outputs that diverge from expected distributions triggers an alert before the action completes.
Detection without the ability to act is just logging.
Runtime protection for AI agents requires the capacity to pause, redirect, or terminate an agent mid-task when its behavior crosses a defined threshold.
Evaluating AI Agent Security Solutions: What Enterprises Must Demand
Here is what a purpose-built agentic AI security platform actually needs to deliver.
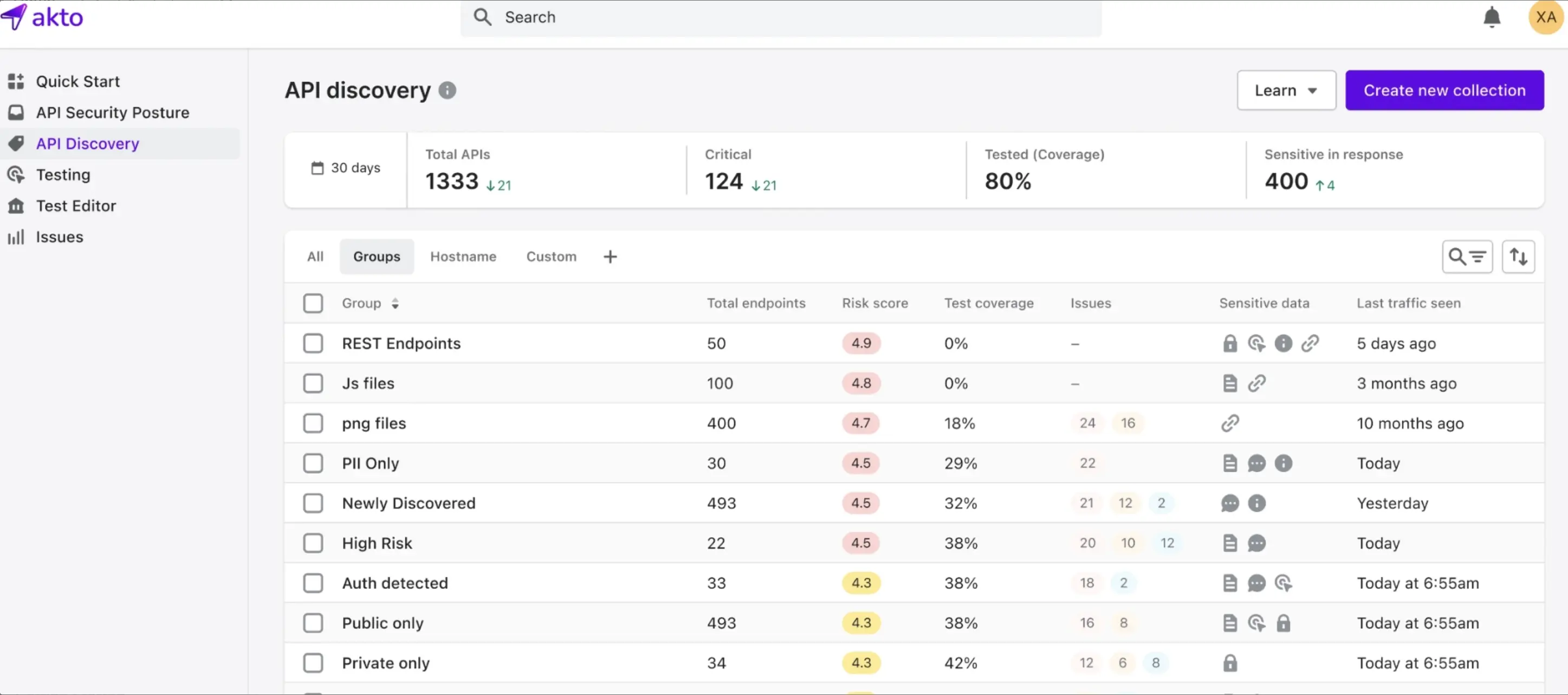
Discovery, Posture Management, and Visibility
You cannot secure what you cannot see. The first requirement is a complete, continuously updated agent inventory.
Most enterprises underestimate how many agents are active. Shadow AI, agents deployed outside formal procurement or IT review, is a real problem and a real risk.
MCP discovery adds a dynamic dimension to that inventory. Because MCP-enabled agents can connect to external services at runtime, the effective perimeter shifts constantly. An agentic AI security platform needs to track those connections as they form, not just audit them later.
Not every agent carries equal risk. Risk scoring via AI agent posture management assigns scores based on permission scope, data sensitivity, behavioral history, and configuration gaps, giving security teams a clear picture of where to focus.
Integration with Enterprise IAM, SIEM, and DevSecOps Pipelines
IAM integration: Agent identities must be governed through the same controls applied to human users. Identity and access for AI agents need to plug into existing provisioning, deprovisioning, and access review workflows. Agents outside IAM governance become blind spots.
SIEM telemetry ingestion: Agent events like anomalous tool calls, policy violations, and behavioral drift should appear alongside other signals in the SOC's existing alert and correlation workflows, not in a separate console.
CI/CD integration: Agent configurations, permission scopes, and prompt templates should pass through security gates before reaching production. Enterprise AI security best practices treat agent deployment the same way they treat application deployment: tested, reviewed, and gated.
Policy orchestration: AI agent compliance requirements, including data residency, access logging, retention, and auditability, cannot be managed agent by agent. They need central definition and platform-level enforcement, verifiable on demand.
Operationalizing Agentic AI Security — Real-World Deployment Patterns
Reference Architectures: Securing Employee and Homegrown Agents
Employee productivity agents: These include calendars, email, internal docs, and HR systems. Zero trust for AI agents here means scoping each agent to the minimum data it needs per session. AI agent guardrails should enforce that scope at runtime, not just at provisioning.
Customer-facing agents: Higher exposure, stricter controls. Sandboxed execution environments prevent a compromised customer-facing agent from reaching internal systems. Output filtering and rate limiting are non-negotiable.
Internal orchestration agents: These coordinate other agents and carry delegated authority. Every delegation must be explicit, logged, and time-bounded. Agentic workflows that pass instructions between agents need trust verification at each handoff.
Secure MCP integrations: Any connector outside an approved list requires explicit review before an agent can invoke it at runtime.
Continuous Enforcement: From Policy to Real-Time Blocking
Runtime enforcement engines: Policies defined at the platform level execute inline with agent actions. Every tool call, data access, and outbound request is evaluated before it completes.
Action interception: Tool call monitoring flags calls that fall outside the agent's expected behavior pattern and holds them pending review. High-risk actions are never executed unreviewed.
Human escalation: For actions above a defined risk threshold, the agent pauses and routes to a human approver. This keeps autonomous agent decision-making within acceptable bounds without stopping low-risk workflows.
Session termination and threat response automation: When AI agent threat detection confirms a breach or manipulation attempt, the response is immediate, thanks to automation.
Akto in Action: Unified Agentic AI Security for the Enterprise
Akto, a purpose-built agentic AI security platform, operates around three layers, i.e., agentic visibility and discovery, continuous red teaming, and runtime guardrails.
Here is how they work in real-time:
How Akto Automates Agentic AI Discovery and Posture Management
Akto automatically discovers and catalogs MCPs, AI agents, tools, and resources across your infrastructure.
MCP discovery runs continuously, so the inventory reflects what is actually running and not what was approved at deployment.
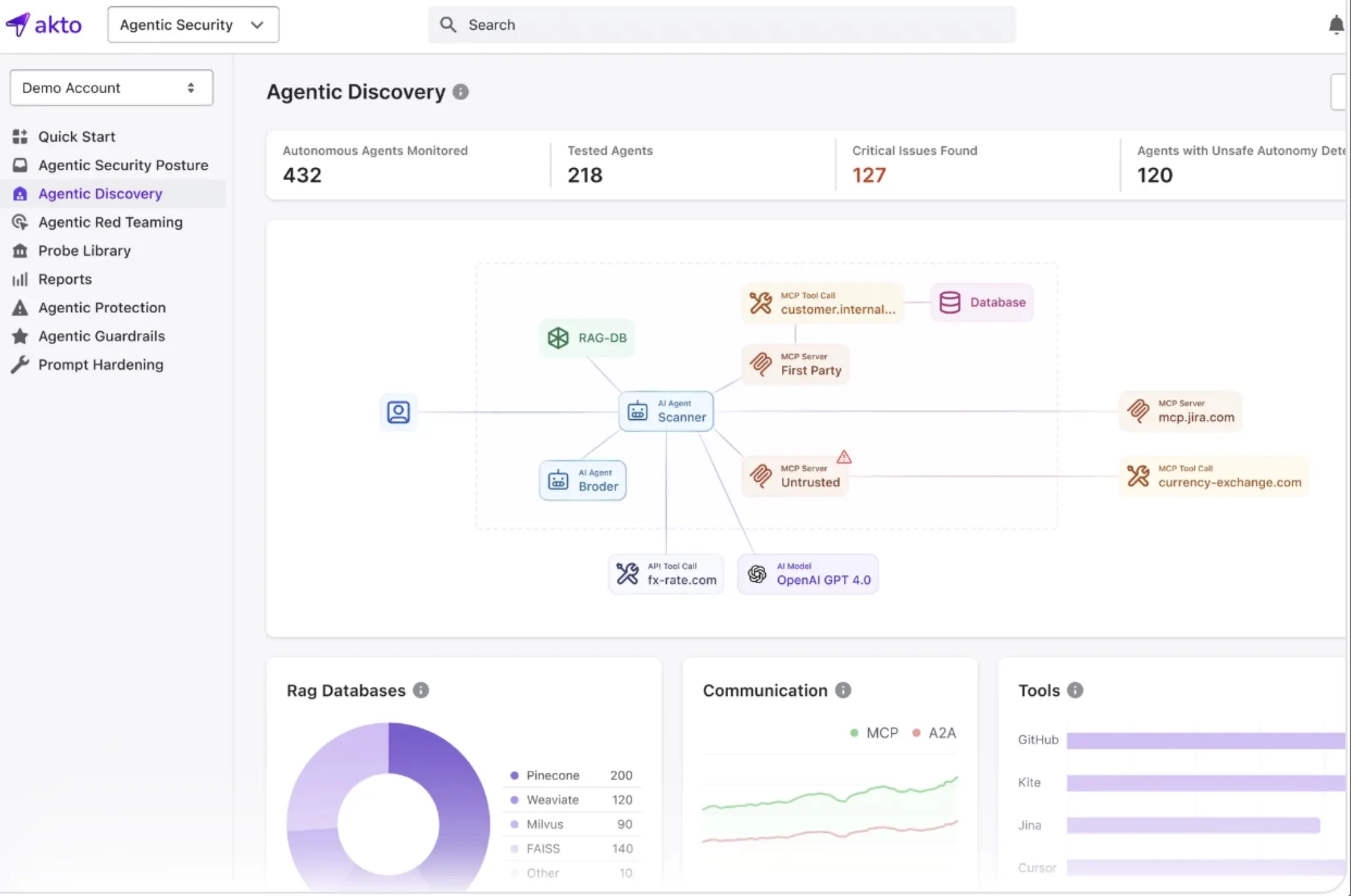
Agent inventory mapping: Every agent gets logged with its tool access, data connections, and permission scope. Akto also identifies shadow AI implementations and unauthorized LLM usage that fall outside formal governance.
Misconfiguration and posture analysis: Akto scores each agent by risk, flagging overpermissioned configurations, unreviewed MCP connections, and policy gaps before they become incidents.
Governance automation: Akto is recognized by Gartner as a representative agentic AI security platform and trusted by Fortune 500 security teams to enforce governance at scale.
Automated Red Teaming and Runtime Protection with Akto
Akto's red teaming runs continuous attack simulations with 1000+ real-world agent exploits.
This covers prompt injection, tool abuse, memory poisoning, and multi-turn attack chains automatically, without manual test scripting.
Runtime protection and AI agent threat detection: Akto's guardrails and runtime protection layer enforce enterprise policies that block risky agent behavior and unauthorized actions in real time.
Compliance reporting: Every agent action, policy trigger, and security event is logged and auditable. Security teams get the evidence trail that AI agent compliance frameworks require, without building custom logging pipelines.
Future Trends and Evolving Challenges in AI Agent Security
AI agents are becoming more autonomous, interconnected, and deeply embedded in business operations.
Security strategies built for today's deployments will need to adapt continuously to keep pace.
Regulatory and Compliance Considerations
The EU AI Act, emerging US federal guidance, and sector-specific mandates are beginning to impose concrete requirements on enterprises running autonomous AI systems.
Agents that operate across regional boundaries carry different compliance obligations in each. Enterprise AI security best practices now include mapping agent data flows against regional requirements before deployment and not after an incident is reported.
The Road Ahead: Adaptive Security for Autonomous Agents
Static guardrails will not hold against agents that grow more capable with each model generation. The agentic AI security platform of the near future will enforce adaptive policies that update based on observed agent behavior, emerging threat patterns, and changes in the agent's operational context.
Self-healing guardrails will detect when a control has been bypassed or degraded and automatically restore enforcement.
However, the hardest problem could be achieving multi-agent governance. As agent pipelines grow deeper, the security boundary extends across dozens of interacting systems.
Final Thoughts on AI Agent Security Solutions
AI agents have moved from experimental to operational across the enterprise, thus upgrading the attack surface.
The enterprises that get this right have runtime visibility into what their agents are actually doing, enforce zero trust principles, run continuous automated red teaming, and use security tooling built specifically for agentic AI.
If your organization is deploying AI agents at scale and wants to understand what your current exposure looks like, Akto can help.
Request AI Security demo and see how the platform maps your agent inventory, runs automated red teaming, and enforces runtime guardrails across your environment.
FAQs
What are AI agent security solutions?
AI agent security solutions are tools built to protect autonomous AI systems at runtime. They cover agent discovery, behavioral monitoring, threat detection, guardrail enforcement, and compliance logging
Why do enterprises need runtime protection for AI agents?
AI agents make decisions dynamically based on live inputs. Runtime protection monitors agent behavior as it happens and intervenes before harmful actions are completed.
How does prompt injection prevention work?
Prompt injection prevention intercepts and evaluates inputs before an agent processes them, flagging patterns consistent with goal manipulation or instruction hijacking. Effective prevention combines input validation, behavioral monitoring, and output filtering.
What is an agentic AI security platform?
An agentic AI security platform, like Akto, is a purpose-built infrastructure for securing AI agents across their full lifecycle. It provides agent inventory and MCP discovery, continuous red teaming, runtime threat detection, and policy enforcement.
Important Links

Experience enterprise-grade Agentic Security solution