

Introducing AgentGuard: Guardrails for Your Agentic AI
Akto AgentGuard provides real-time guardrails for agentic AI, enforcing runtime policies across AI agents, MCPs, tools and LLM interactions.

Akash
Modern AI systems aren’t just responding to prompts anymore. They’re acting autonomously calling tools, triggering workflows, and executing actions on your behalf.
While this unlocks incredible capabilities, it also introduces a fundamental problem:
How do you keep agentic AI safe, predictable, and aligned with your organizational policies in real time?
Today, security teams have limited visibility into these systems and even less control. Once these agents are deployed, every action becomes a potential risk surface, often invisible until something breaks.
In fact, 79% of the organizations don’t yet have guardrails or governance policies for AI agents and MCPs.

That means:
Unsafe tool calls are executed before anyone notices
Privilege escalation happens through multi-step reasoning
Sensitive data is accessed or exfiltrated without violating any single rule
The Control Gap in Agentic Systems
Controlling how AI agents behave in real time is one of the hardest challenges in enterprise AI security.
Across real-world deployments, we consistently see the same gaps:
No consistent policy enforcement across agents and MCP servers
Over-reliance on static prompts or model defaults
No protection against prompt injection or intent drift
Limited controls for sensitive data exposure
No way to validate agent behavior before actions execute
When something goes wrong, it usually happens silently. Without runtime guardrails, failures are only discovered after an incident occurs.
That’s why we built AgentGuard.
Introducing AgentGuard
AgentGuard is Akto’s real-time guardrails module for Agentic AI. It gives security teams direct control over what agents can and cannot do, at the exact moment actions are attempted across AI agents, MCPs, LLMs, and GenAI applications.
AgentGuard is built for the reality of agentic systems: autonomous, dynamic, and constantly evolving.
What AgentGuard Enables?
With AgentGuard, organizations can:
Enforce policies at runtime
Block unsafe actions before tools are invoked or data is accessed.
Control agent behavior, not just prompts
Evaluate intent, context, and downstream impact-not just input/output text.
Prevent privilege escalation and unsafe automation
Stop agents from chaining actions beyond approved scopes.
Standardize governance across agents and MCPs
Apply consistent guardrails across teams, tools, and environments.
This isn’t about slowing teams down, It’s about enabling innovation without losing control.
How AgentGuard Works
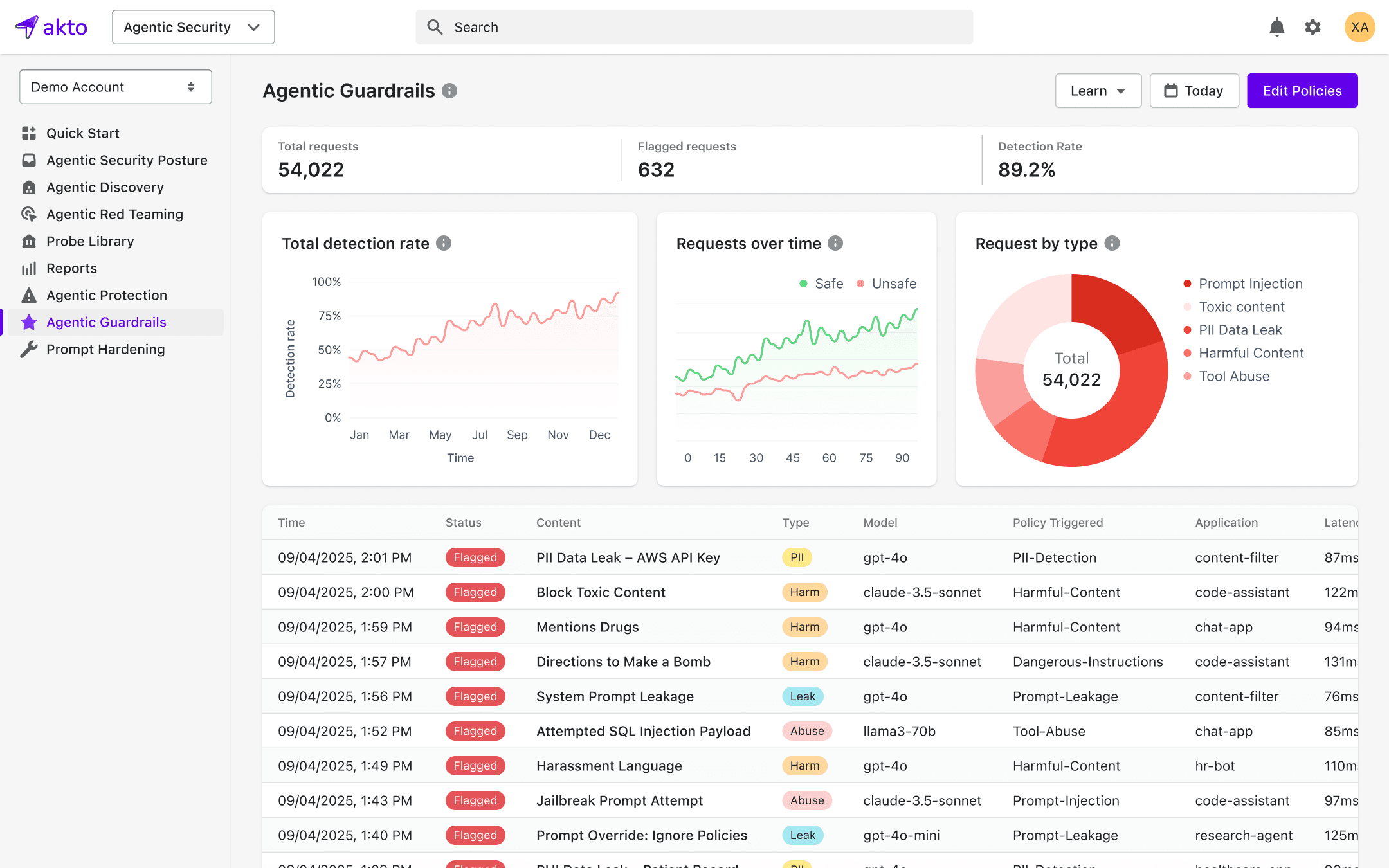
AgentGuard operates as a runtime enforcement layer in your agentic architecture.
It intercepts:
Agent actions
MCP requests
Tool invocations
LLM interactions
Before execution, AgentGuard evaluates these actions against enterprise-defined guardrail policies, enforcing decisions in real time.
Because enforcement happens during execution, not after:
Risky actions are blocked immediately
Unsafe requests never reach downstream systems
Violations don’t rely on human review to be caught
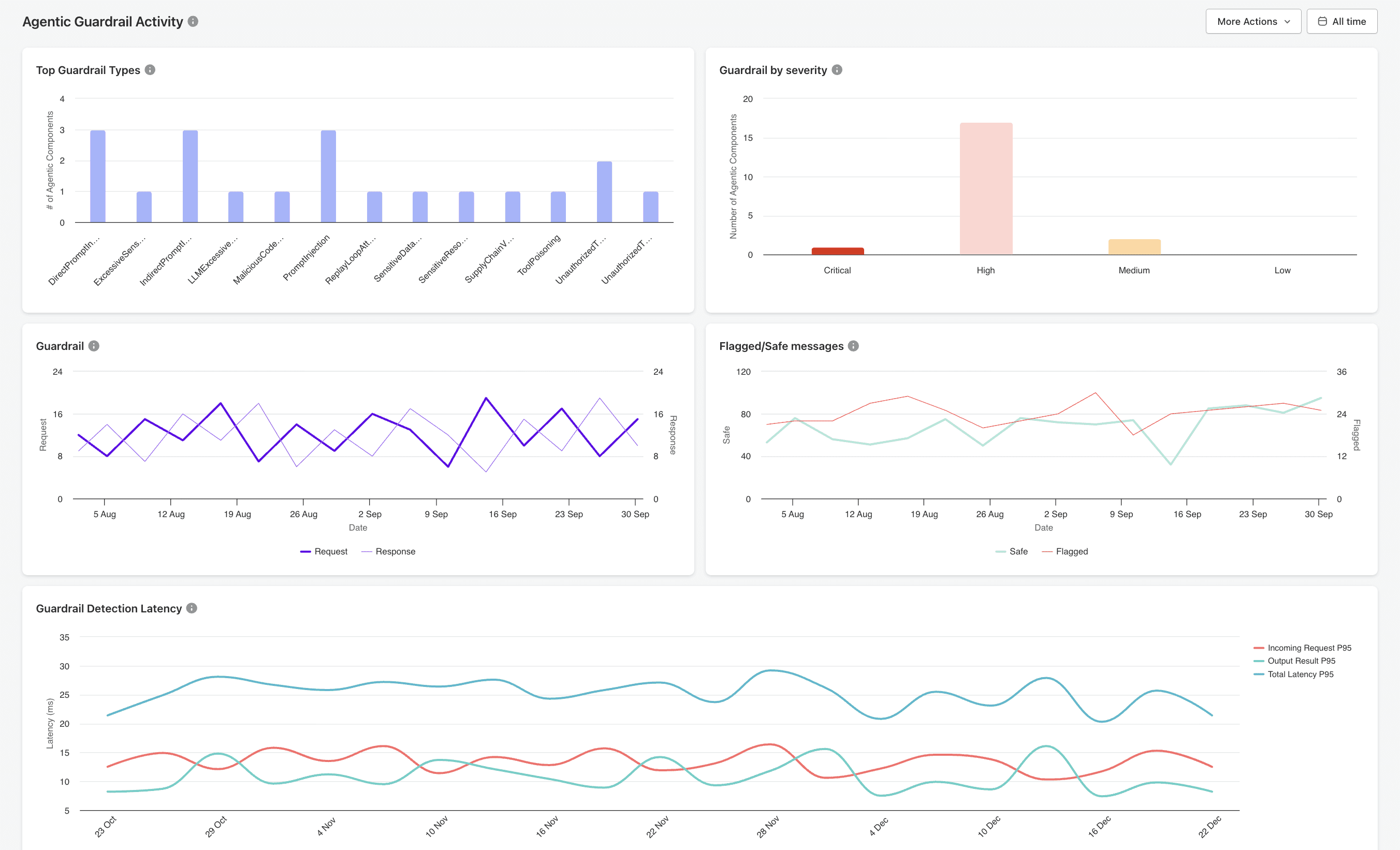
Built-In Guardrail Controls
AgentGuard includes a comprehensive set of runtime controls that work together to keep agent behavior safe and predictable.
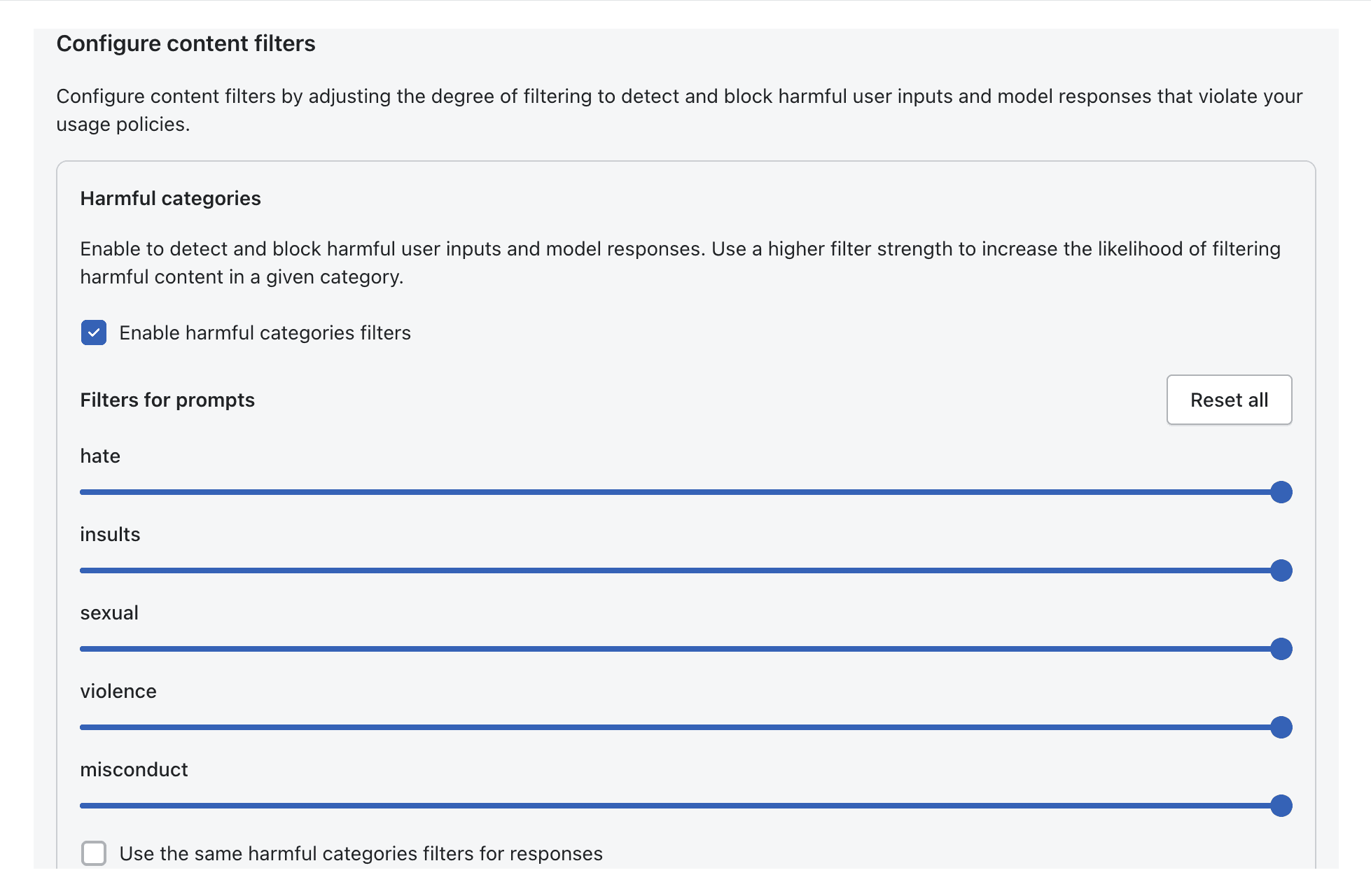
Harmful content filtering
Detect and block unsafe categories like hate, violence, and harassment across both inputs and model outputs.
Prompt attack protection
Prevent attempts to bypass safety rules, including prompt injection or manipulation designed to override system instructions.
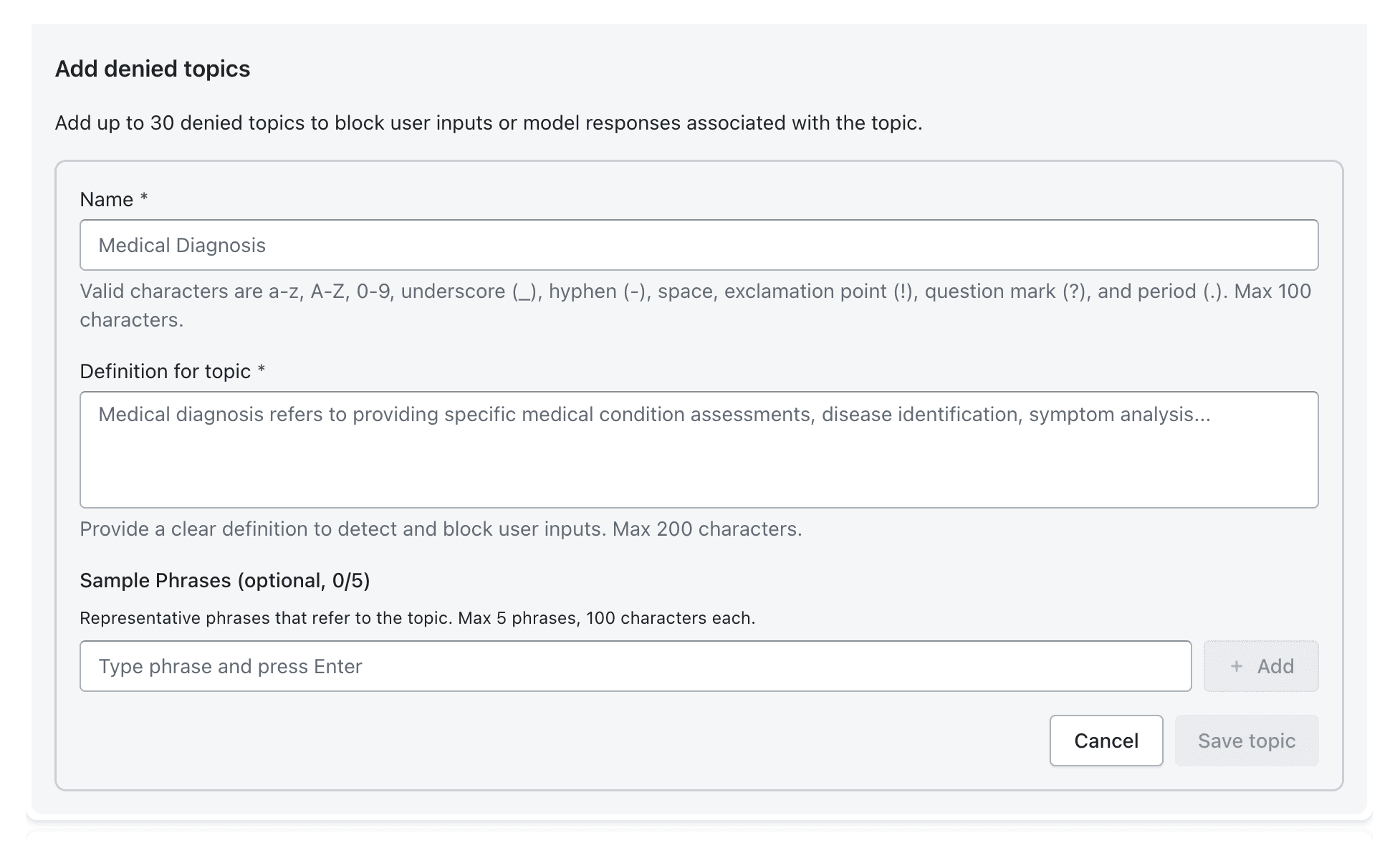
Denied topics
Fully block regulated or high-risk domains like medical advice or investment recommendations — ensuring these actions never execute.
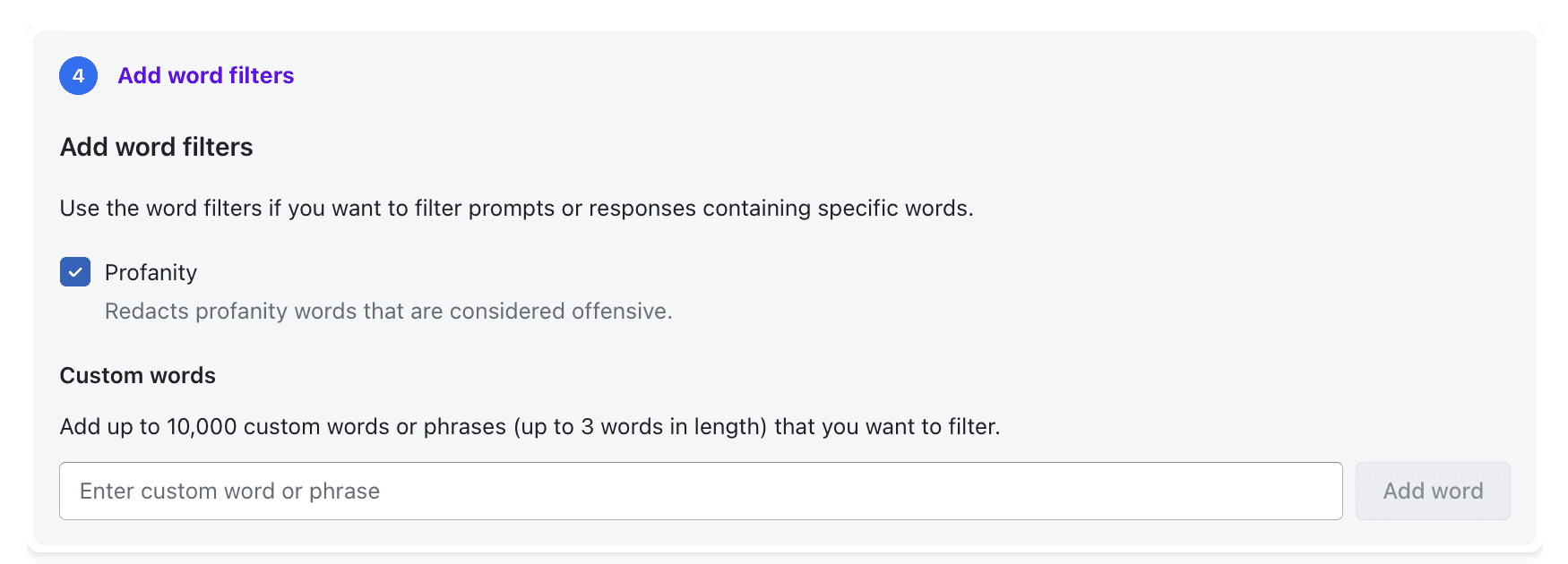
Custom word filters
Filter specific words or phrases based on your organization’s risk profile or internal governance requirements.
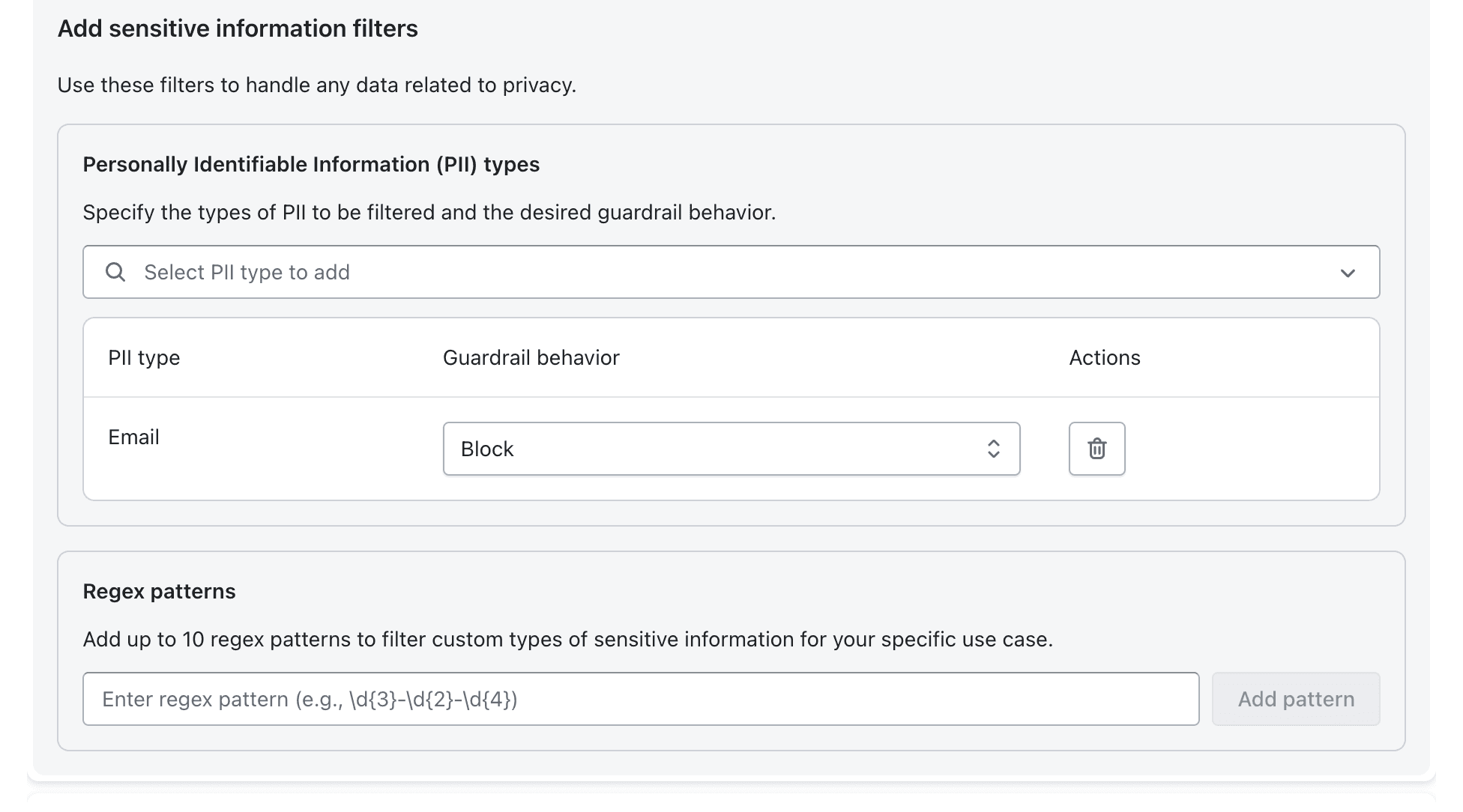
Sensitive data protection
Proactively block personally identifiable information (PII) and custom regex patterns so that sensitive data never slips through your agents.
Intent Verification
Ensure that agents act within their assigned purpose. Requests that deviate from expected behavior can be automatically rejected, keeping workflows safe and predictable.

Advanced Guardrails for Agentic AI
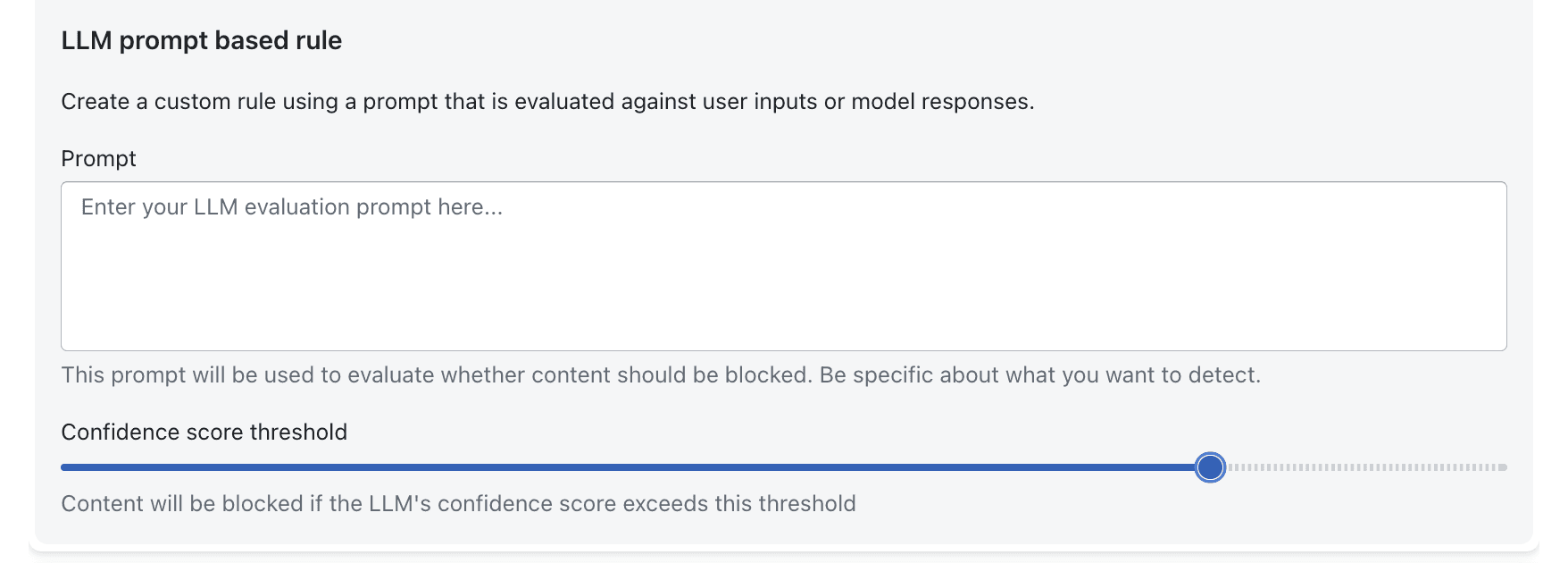
LLM-Based Evaluation
AgentGuard isn’t limited to static rules. You can define LLM prompt-based rules that evaluate intent and content dynamically using natural language prompts you specify.
Instead of relying on rigid patterns, AgentGuard can:
Use your custom prompts to assess whether content should be blocked
Evaluate with confidence scoring to reduce false positives
Apply nuanced judgments that reflect your internal policies
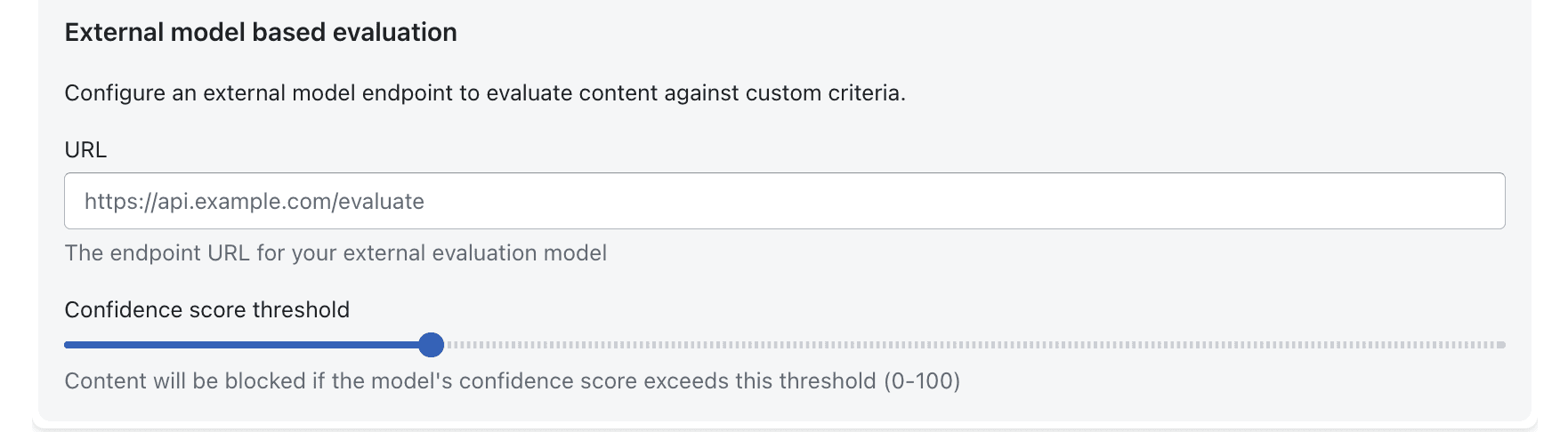
Plug-In Your Own Evaluation Model
For regulated industries or high-assurance environments, dual checks are essential.
AgentGuard allows you to configure an external model endpoint to independently evaluate content or intent. You can combine internal guardrails with third-party scoring to enforce even stricter policies.
Applied Where You Need It Most
Not all environments are the same. and neither are your policies.
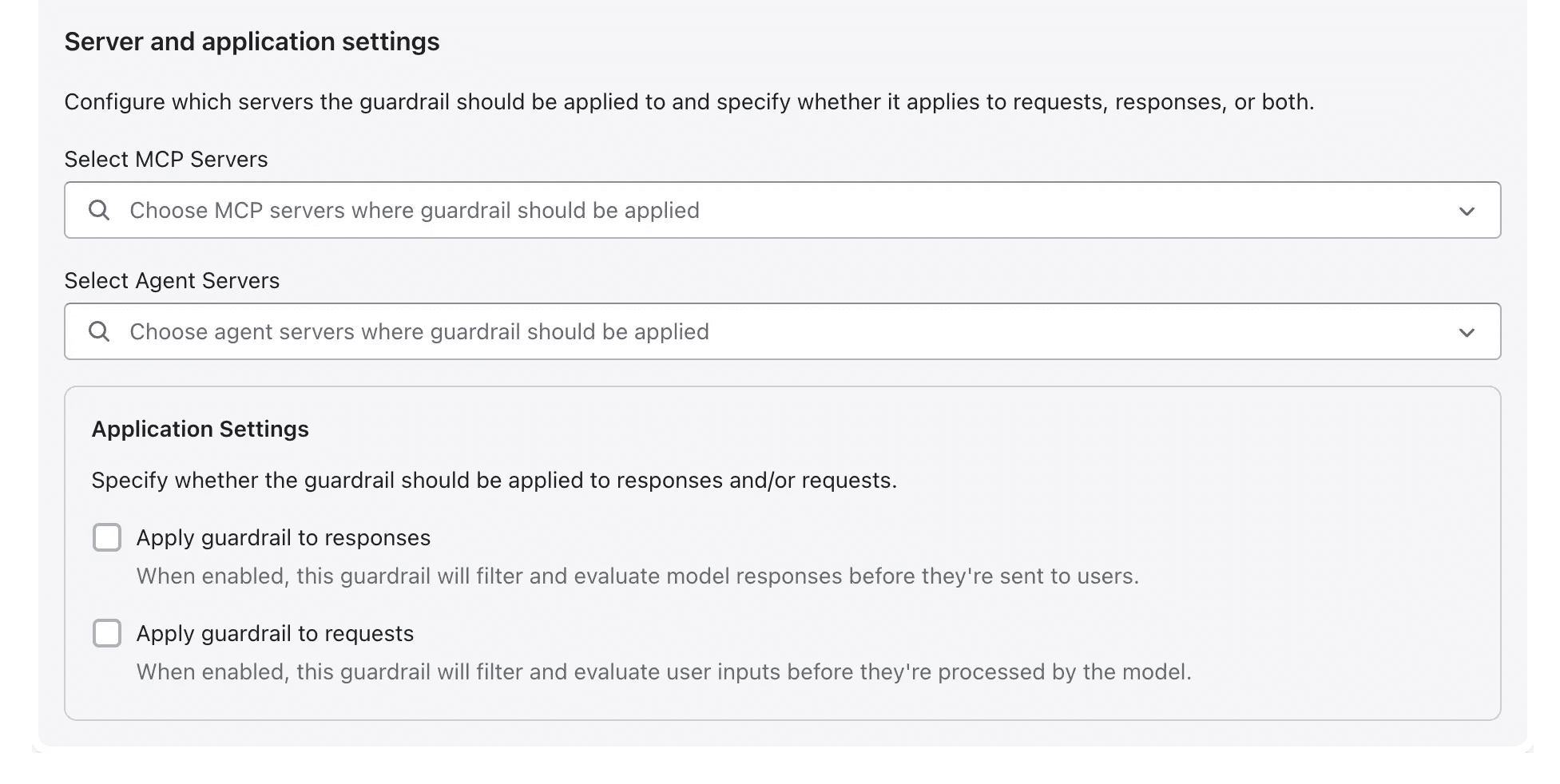
AgentGuard gives you granular control over where policies apply:
Choose specific MCP servers
Target individual agent servers
Enforce at the request or response layer
This flexibility means you can tailor guardrails to specific applications, use cases, and risk levels without disrupting your overall AI workflows.
Bringing Governance and Confidence to Agentic AI
With AgentGuard, you can unlock the power of autonomous AI - without sacrificing control, safety, or compliance.
AgentGuard is a core pillar of Akto’s agentic security platform.
It works alongside:
Agent Discovery - to map every agent, MCP, and tool
Agent Probe - to proactively break workflows before attackers do
Together, they give organizations full visibility, testing, and control across the AI lifecycle.
Ready to see AgentGuard in action? Schedule a demo here
Important Links

Experience enterprise-grade Agentic Security solution