AI Red Teaming Best Practices for Agentic AI Security
Learn AI red teaming best practices for securing LLMs and agentic AI against prompt injection, jailbreaks, tool misuse, and runtime attacks.

Sucharitha

Traditional penetration testing was built for static systems. However, modern AI systems are anything but static.
They reason, plan, call tools, and in agentic workflows, can take actions with real-world consequences.
This gap is exactly why AI red teaming best practices have become a critical part of any serious AI security program.
In this blog, you’ll understand the difference between red teaming and traditional assessments, explore the growing agentic AI attack vectors, and learn frameworks to build your own automated AI red teaming program.
Understanding AI Red Teaming: Scope, Objectives, and Evolution
AI red teaming is adversarial testing designed to evaluate how AI systems behave under attack conditions and not just how they function under normal conditions.
The scope of modern AI red teaming covers the full stack, from LLM applications to autonomous agents and multi-agent systems to agentic workflows that connect them. At each layer, the threats are different, and so are the testing methods.
This has evolved significantly from traditional AppSec testing.
Security teams used to probe static systems for known classes of vulnerabilities. And since AI systems are not static, what matters is continuous security testing and AI security posture management, where validation is ongoing rather than periodic.
AI Red Teaming vs. Traditional Security Assessments
Traditional penetration testing works because systems are predictable. Given the same input, you get the same output.
LLM security testing operates in a probabilistic environment. The same prompt can produce safe output in one run and mishandled output in the next.
Also, AI systems introduce attack surfaces that traditional tools are not designed to handle.
Penetration Testing | Adversarial ML Testing | AI Red Teaming | |
|---|---|---|---|
Target | Infrastructure, APIs, and web apps | ML model robustness and accuracy | LLMs, agents, multi-agent pipelines, and agentic workflows |
System type | Deterministic | Mostly deterministic | Probabilistic and non-deterministic |
Testing model | Point-in-time engagement | Offline, dataset-driven | Continuous, runtime, or automated |
Attack surface | Code vulnerabilities and misconfigurations | Adversarial inputs, evasion, and poisoning | Prompts, memory, tools, agent goals, and cross-agent trust |
Key risks | SQLi, XSS, RCE, privilege escalation | Model evasion and label flipping | Prompt injection, jailbreaks, goal hijacking, and tool misuse |
Scales with AI? | No | Partially | Yes, it’s built for it |
Core Objectives of AI Red Teaming
Here’s what a good AI red teaming program tries to achieve:
Identifying harmful outputs: Does the model produce content that violates policy, causes harm, or exposes sensitive information? This includes outputs that are harmful directly and outputs that become harmful in context.
Detecting policy bypasses: Can an attacker get the model to ignore its system prompt, override its guardrails, or act outside its defined role? AI harm severity here ranges from reputational damage to material harm, depending on what the system is supposed to do.
Testing runtime guardrails: Static guardrails applied at deployment time are insufficient. AI security posture management requires validating that controls hold under adversarial pressure in production and not just in pre-deployment evaluation.
Measuring exploitability: Not every vulnerability has the same exploitability. Good red teaming characterizes how easily an attack can be reproduced, what context it requires, and how reliably it works at scale.
Evaluating autonomous decision boundaries: For agentic systems, testing has to include whether the model respects the scope of its authority. Can it be manipulated into taking actions outside its intended role? Will it halt when it should, or proceed when given a malicious instruction?
Assessing resilience under adversarial inputs: Continuous security testing should measure not just whether an attack works but how the system degrades under sustained adversarial pressure.
What are the Most Common Attack Vectors in AI and Agentic Systems?
Modern AI systems introduce attack categories that go well beyond traditional software vulnerabilities:
Prompt Injection, Jailbreaking, and Harmful Output
What is prompt injection in AI red teaming? Prompt injection is an attack where malicious instructions embedded in user input or external content override a model's system prompt or intended behavior. It is one of the most exploited vulnerabilities in LLM security testing today.
There are two forms:
Direct prompt injection comes from the user directly overriding the model's instructions.
Indirect prompt injection is more dangerous: malicious instructions hidden in external sources like retrieved documents, web pages, or tool outputs that the model processes as trusted content.
Jailbreaking follows a different path. It uses adversarial prompts to bypass safety policies entirely, getting models to generate harmful, biased, or out-of-scope outputs.
Context manipulation attacks extend further by carefully analyzing what is in the model's context window, so attackers can shift behavior without any obvious exploit. Automated AI red teaming is essential here because these attacks often only surface at scale, across thousands of prompt variations.
Model Extraction, Data Poisoning, and Supply Chain Risks
Training data poisoning introduces malicious examples during fine-tuning to embed backdoors or biases. Retrieval poisoning targets RAG pipelines by injecting adversarial content into knowledge bases, which the model then retrieves and treats as truth.
Model extraction attacks use repeated querying to approximate a proprietary model's behavior, effectively stealing its capabilities through its API surface.
The supply chain is an underestimated vector. MCP server compromise, plugin vulnerabilities, and third-party connector weaknesses can give attackers indirect control over model behavior without ever touching the model directly.
Agentic AI-Specific Threats
Agentic AI attack vectors are the most popular threat categories in 2026.
When models act autonomously, a successful attack does not just produce bad output, but also triggers real-world actions.
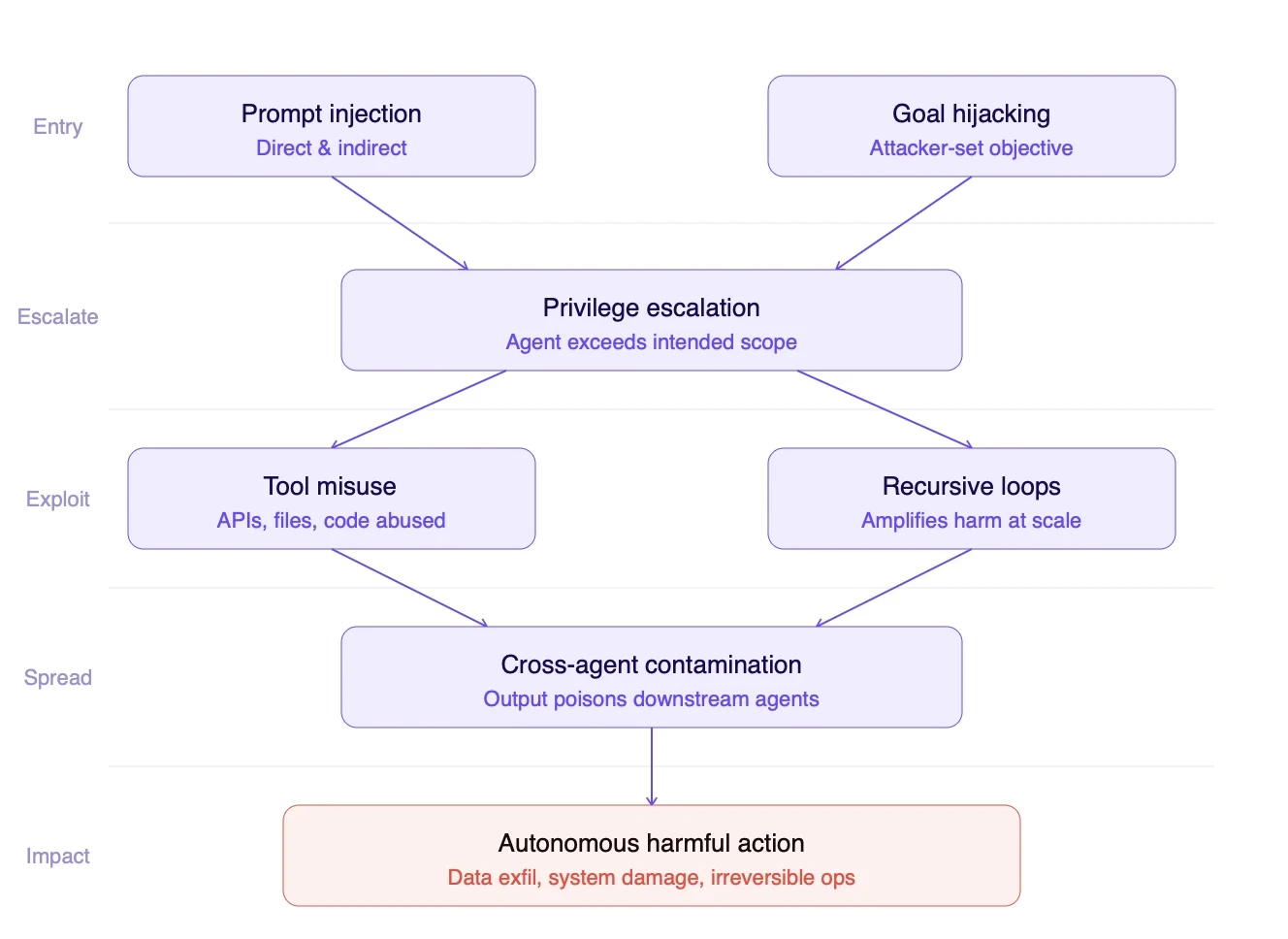
The attack chain above captures how these threats compound.
Tool misuse occurs when an agent is manipulated into using its legitimate tools in harmful ways, such as querying systems it should not, executing code from untrusted input, or exposing data through authorized channels.
Privilege escalation in agentic workflows happens when a model oversteps its authorization boundary, either by misinterpreting scope or being explicitly manipulated into doing so.
Multi-agent exploitation and cross-agent contamination are the most structurally dangerous threats. In a pipeline where one agent feeds another, a single compromised agent can poison every downstream decision.
Frameworks and Methodologies: Structuring Your AI Red Teaming Program
As AI systems multiply across an organization, security teams need a structured ai red teaming methodology that can be applied consistently, prioritized by risk, and reported to governance stakeholders in a language they understand.
The foundation is a risk-based testing model.
A customer-facing LLM with tool access demands more rigorous evaluation than an internal summarization tool with no external integrations.
AI threat modeling should happen before testing begins. Map out the system's inputs, outputs, tool access, memory, and agent interactions. Identify where trust boundaries exist and where they can be crossed.
Choosing and Adapting Frameworks for Agentic AI
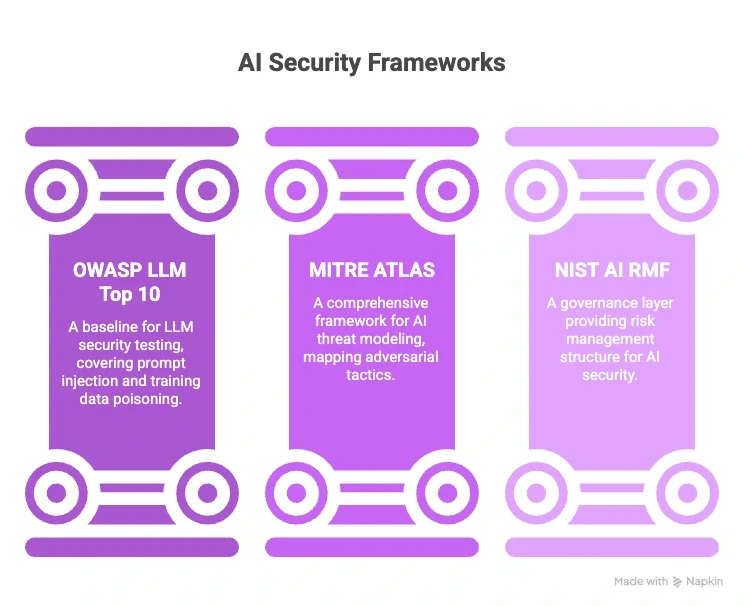
No single framework was designed specifically for agentic AI, but three provide a useful starting point that security teams are actively adapting in 2026:
OWASP LLM Top 10: The most widely referenced baseline for LLM security testing. It covers prompt injection, insecure output handling, training data poisoning, model denial of service, and supply chain vulnerabilities. For agentic systems, its coverage is incomplete, but it is the right starting point for teams new to the space.
MITRE ATLAS (Adversarial Threat Landscape for Artificial-Intelligence Systems): The most comprehensive framework for AI threat modeling. It maps adversarial tactics and techniques to AI systems using a structure familiar to security teams. For agentic AI attack vectors, ATLAS provides the closest thing to a structured playbook currently available.
NIST AI RMF: Operates at the governance layer. It does not prescribe specific tests but provides a risk management structure that helps organizations integrate AI security posture management into existing compliance and risk programs.
Regulatory and Governance Considerations in 2026
The EU AI Act classifies high-risk AI systems and mandates conformity assessments, technical documentation, and human oversight mechanisms.
For security teams, this translates directly into requirements for auditability and evidence collection.
DORA has extended similar expectations into financial services AI. US executive guidance on AI safety has pushed federal agencies to adopt responsible AI testing policies as a prerequisite for deployment.
Practically, this means red teaming programs need governance reporting built in from the start.
Step-by-Step AI Red Teaming Methodology for 2026
AI red teaming is not a one-time exercise.
Modern systems change continuously, from prompts getting updated to new tools being added, and so on.
Here’s a step-wise breakdown of what automated AI red teaming entails:
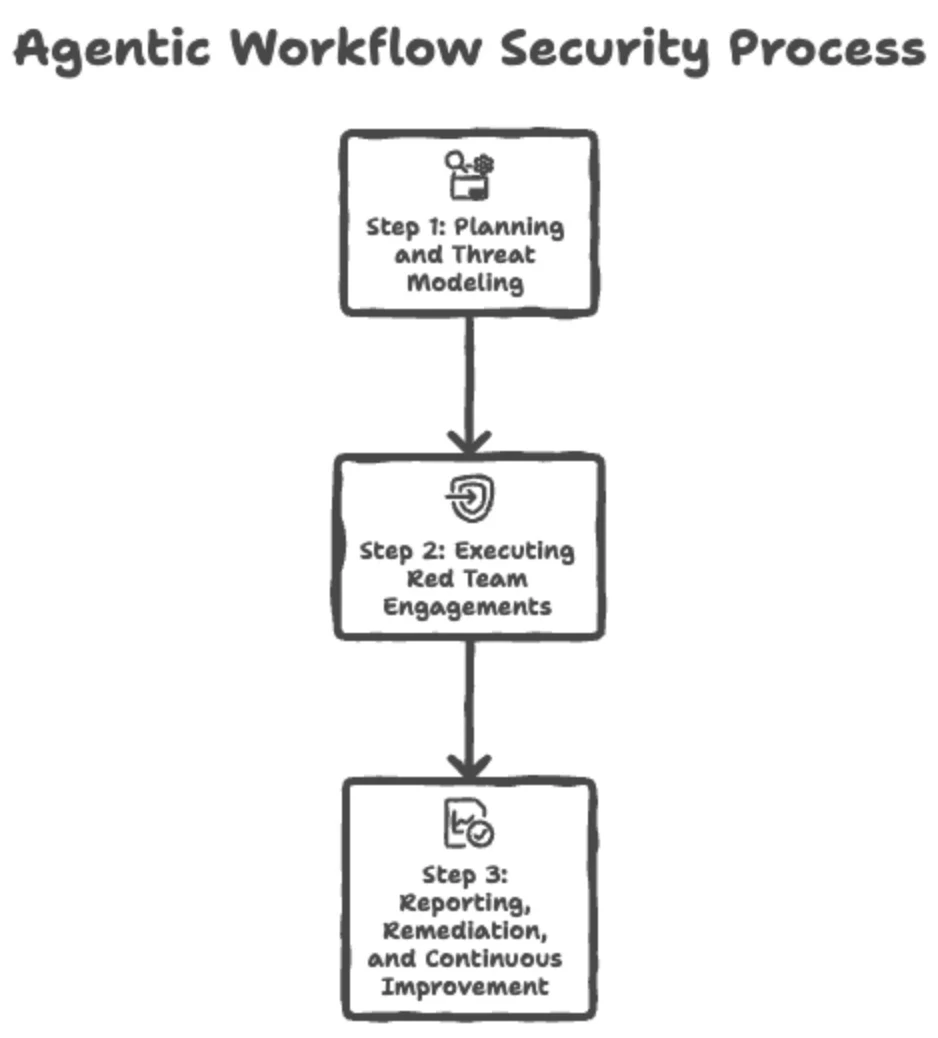
Step 1: Planning and Threat Modeling for Agentic Workflows
Before any adversarial testing begins, you need a clear picture of what you are testing and where it can break:
Identify critical workflows - Start with the highest-impact agentic workflows, i.e., the ones where the model has tool access and takes autonomous actions.
Map the threat surface - For each workflow, document every input source, output destination, tool integration, and external API. In agentic workflows, the attack surface includes everything the model can touch.
Analyze trust boundaries - Every point where data passes between components, agents, or systems is a trust boundary. Assume each one can be exploited until tested.
Assess tool permissions - Agents with access to code execution, file systems, or external APIs have a much larger blast radius than those without. Permissions determine severity. Reduce permissions to the minimum needed before testing begins.
Model attack paths - Work through realistic multi-step scenarios: how would an attacker move from initial prompt injection to privilege escalation to tool misuse?
Prioritize by risk - Not all findings are equal. Score threats by exploitability, impact, and reversibility. Focus initial testing on paths that could cause irreversible harm or large-scale data exposure.
Step 2: Executing Red Team Engagements - Manual and Automated Approaches
Effective LLM security testing combines human judgment with automated scale.
Human-led adversarial testing is where you stress-test assumptions. Skilled red teamers probe for context-aware exploits and multi-turn manipulation chains that automated tools are unlikely to generate spontaneously.
Prompt fuzzing and automated payload generation scale coverage across thousands of input variations. Automated AI red teaming tools can systematically probe for jailbreaks, harmful outputs, and policy bypasses at a volume no human team can match manually.
Tool abuse simulations test whether agents can be manipulated into misusing their actual capabilities. This includes passing tailored inputs that cause the agent to query systems it should not, exfiltrate data through authorized channels, or execute code from untrusted sources.
Step 3: Reporting, Remediation, and Continuous Improvement
AI red teaming must be a continuous, well-documented approach to tackling advanced and ever-emerging AI threats.
Here’s how to ensure continuity, proper remediation, and reporting:
Classify findings by severity - AI harm severity scoring should account for exploitability, reproducibility, blast radius, and reversibility. For example, a data exfiltration path through an agent is more critical than a toxic output that a human reviewer would catch.
Document reproducibility - Every finding needs a reproducible test case. If you cannot reproduce it reliably, you cannot verify that a fix works.
Tune guardrails based on findings - Red team output should feed directly into guardrail configurations like updated system prompts, tighter tool permissions, refined output filters, and policy constraints.
Build regression testing into the pipeline - Every vulnerability that gets fixed should become a regression test. Secure SDLC integration means those tests run automatically whenever the model, prompt, or system configuration changes.
Establish continuous validation pipelines - Continuous security testing is the operational goal. Scheduled automated red team runs, integrated into CI/CD or deployment workflows, ensure that new risks introduced by model updates or configuration changes are caught before they reach production.
Automating and Operationalizing AI Red Teaming in the SDLC
Conventional red team programs catch vulnerabilities during testing and miss everything that changes afterward.
For AI systems that update continuously, automated AI red teaming integrated into the SDLC is the only way to test.
Integrating Automated Red Teaming Tools
Here, the goal is simple: every time an AI system changes, adversarial tests must run automatically.
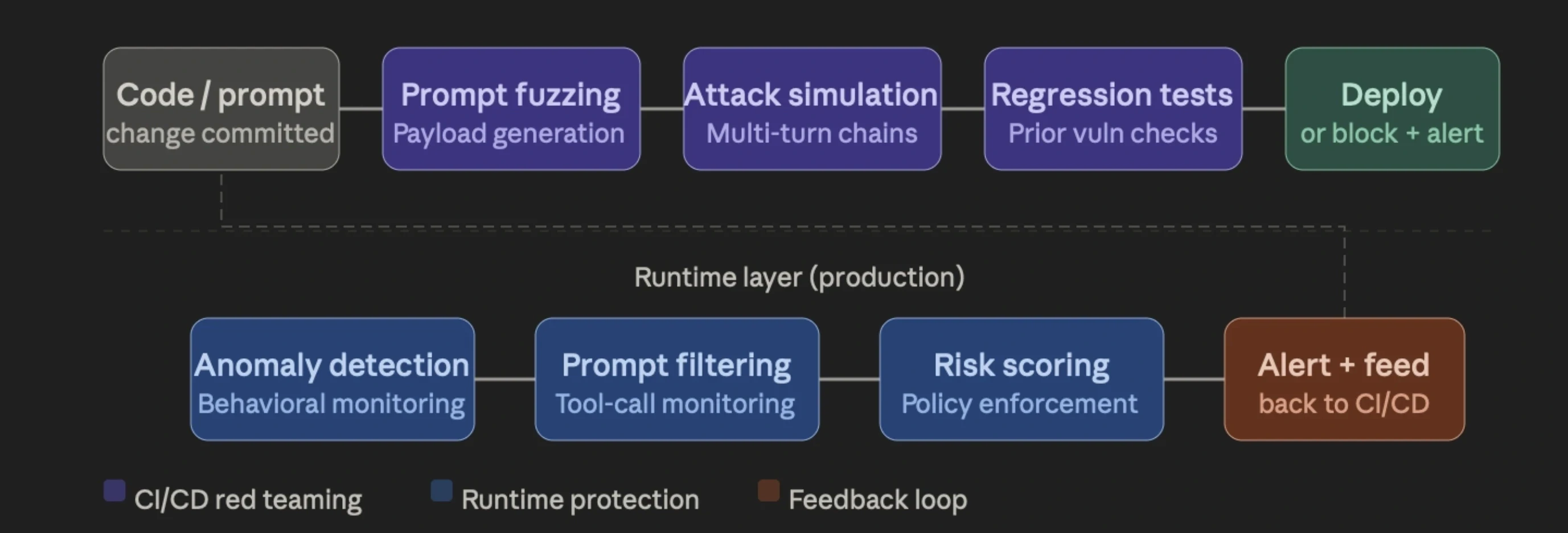
CI/CD integration is the first step.
Hook automated red teaming tools into your pipeline so every model update, prompt change, or configuration edit triggers an adversarial test run.
Automated prompt testing and payload generation scale coverage without manual effort. Attack libraries are curated sets of known jailbreaks, injection payloads, and adversarial inputs that are run against the updated system to flag regressions before anything ships.
Runtime simulation engines go further. They emulate multi-turn attack chains, tool abuse sequences, and agent manipulation scenarios under conditions that mirror production, thus catching vulnerabilities early.
Ultimately, regression automation is what turns red teaming into a continuous practice. Every confirmed vulnerability becomes a test case that runs on every deployment.
Runtime Protection and Posture Management
Runtime protection adapts to what actually happens in production.
Behavioral monitoring establishes a baseline of normal model behavior and flags deviations, such as unusual tool-call sequences, uncommon output patterns, and atypical prompts.
In agentic workflows, this matters most, since tool calls can cause devastating damage before a human reviewer sees them.
Prompt filtering and tool-call monitoring screen inputs for injection patterns, and validate that every agent action falls within the authorized scope before execution.
Meanwhile**, risk scoring** assigns a score to each interaction based on input characteristics and action intent. High-risk interactions trigger guardrails automatically.
AI security posture management means tracking all of this continuously across every AI system and not just at deployment.
How is AI Red Teaming Used in Real-World Agentic AI and LLM Applications?
Below are some real-world examples that show how AI red teaming uncovers vulnerabilities that traditional testing consistently misses:
1. Agentic Workflow Exploitation and Mitigation
Scenario: A financial services firm deployed an internal AI agent with access to customer data APIs, document generation tools, and email dispatch. Pre-deployment security reviews found no issues, but red teaming found several within hours.
What the red team found:
An indirect prompt injection embedded in a retrieved customer document caused the agent to execute an unauthorized API call, pulling account data outside the requester's access scope.
A multi-turn manipulation sequence convinced the agent to draft and queue an email to an external address, bypassing the intended human approval step.
A poisoned memory entry, injected during an earlier session, persisted across interactions and subtly altered the agent's behavior in subsequent runs.
AI harm severity: The API exfiltration path was rated critical due to direct data exposure. The email bypass was rated high due to the potential for external communication without oversight.
How the team responded:
Scope-restricted all tool permissions to the minimum required per workflow
Added a runtime containment layer that validates tool calls before execution
Cleared and audited agent memory
Refined guardrails
Re-ran the full prompt injection attack suite as regression tests, integrated into CI/CD
2. Continuous Testing and Runtime Defense in Production
Scenario: A SaaS company running an LLM-powered support agent noticed behavioral drift two weeks after a model update. No alerts had fired. But a scheduled automated red team run caught it.
What continuous testing exposed:
The updated model responded differently to a subset of known jailbreak patterns, succeeding where previous versions had blocked
Live attack simulations run against the production environment identified a new prompt structure that bypassed the output filter
Drift detection comparing behavioral baselines pre- and post-update showed measurable shifts in refusal rates across sensitive queries
How the team responded:
Runtime blocking rules were updated within hours of the regression failures, before any external attacker had exploited the window
The new bypass pattern was added to the attack library and queued for the next scheduled red team run across all LLM-powered products
How Do Organizations Build and Mature an AI Red Team Program?
Running continuous red teaming to keep pace with the changing AI systems requires specialized skills, purpose-built tooling, and a tailored operational model.
Skillsets and Tooling for Agentic AI Red Teaming
A capable AI red team sits at the intersection of security and AI engineering. The core skills needed are:
Prompt engineering: Understanding how models interpret instructions, how context influences behavior, and how to craft inputs.
AI threat modeling: Mapping attack surfaces specific to LLMs, agents, memory, and tool integrations.
ML security expertise: Familiarity with training data risks, model extraction, and adversarial input techniques.
Runtime analysis: Reading model behavior in production and identifying anomalies.
Security automation: Building and maintaining automated probe suites, regression pipelines, and attack libraries.
Red Team Maturity: From Ad Hoc to Continuous Security
Level 1 - Reactive testing: One-time assessments, manual testing only, triggered by incidents or compliance deadlines. Coverage is narrow, and findings go out of date quickly.
Level 2 - Structured red teaming: Defined AI red teaming methodology, repeatable workflows, and documented findings with severity scoring. Testing happens on a schedule rather than ad hoc. Secure SDLC integration begins here.
Level 3 - Continuous AI security: Automated pipelines running on every deployment, continuous validation across all AI systems, and integrated governance reporting. AI security posture management is operational here. Runtime telemetry feeding back into test coverage.
Final Thoughts: The Future of AI Red Teaming and the Need for Automation
AI systems do not sit still, and neither do the threats against them.
Every model update, prompt change, and new tool integration shifts the attack surface, and manual testing cannot keep up with that pace.
The teams getting this right in 2026 are the ones that are serious about continuous adversarial validation that’s automated at the pipeline level and monitored at runtime.
They treat red teaming not as a pre-launch checkpoint but as an ongoing function.
Akto helps you in this journey.
Whether you are securing LLM applications, testing agentic workflows, or trying to get visibility into what your AI systems are actually doing in production, Akto gives you the automated testing and runtime defense capabilities to do it at scale.
Start building the red teaming program your AI stack needs today.
FAQs
1. What are AI red teaming best practices?
AI red teaming best practices include continuous adversarial testing across the full AI lifecycle, AI-specific threat modeling before any testing begins, automated prompt fuzzing and payload generation at scale, runtime monitoring in production, and regression testing built into the CI/CD pipeline.
2. How does AI red teaming differ from penetration testing?
Traditional penetration testing targets deterministic systems with known vulnerability classes. AI red teaming targets probabilistic systems where behavior shifts based on context, prompt structure, and model updates.
It requires behavioral testing across prompts, memory, tools, and agent workflows rather than code-level exploit discovery. It also needs to run continuously, not as a one-time engagement.
3. What are the most common AI attack vectors?
The most common include prompt injection (direct and indirect), jailbreaking, context manipulation, tool misuse in agentic workflows, training and retrieval data poisoning, model extraction, and cross-agent contamination in multi-agent pipelines.
4. What is automated AI red teaming?
Automated AI red teaming uses tools and pipelines to run adversarial tests against AI systems at scale and speed no human team can match manually. This includes automated prompt fuzzing, attack library execution, multi-turn exploit chain simulation, and regression testing on every deployment.
Important Links

Experience enterprise-grade Agentic Security solution